MDM - Master Data Management
O MD2 MDM é construído na plataforma IBM Information Server®, uma suite robusta de integração de dados, que permite a visão consolidada de todos os ativos da empresa, considerando os fatores críticos para desafios de integração e tratamento de qualidade de dados. Os componentes da plataforma são combinados para criar uma base unificada para arquiteturas de informações corporativas, capazes de ajuste de escala para atender a diversos requisitos de volume e complexidade de integrações.
- 1. Carga da Base de Referência
- 2. Controle de Carga
- 3. Extração de Dados dos Legados
- 3.1. Estratégia de Views
- 3.2. Camada STG
- 3.3. Camada BCR De-Para Domínio
- 3.4. Domínio de Classificação dos Atributos MDM
- 4. Esteira de Qualidade de Dados
- 4.1. Regras de Padronização
- 4.2. Enriquecimento de Dados
- 4.3. Crítica de Dados
- 4.4. Matching
- 4.5. Sobrevivência
- 5. Curadoria de Dados
- 5.1. Consulta Pessoas
- 5.2. Tratamento de Dados Inválidos
- 5.3. Tratamento de Duvidosos
- 5.4. Cadastro e Edição de Golden Records
- 6. Publicação de Dados
- 6.1. Publicação por Serviços Web (SOA)
- 6.2. Publicação por Filas de Mensageria
- 6.3. Publicação de Arquivos
- 6.4. Publicação por Integração de Dados (ETL)
- 7. Histórico e Rastreabilidade no MDM
- 8. Representação de Relacionamentos no MDM
- 8.1. House Holding
- 8.2. Estrutura de Relacionamento
- 8.3. Apresentação de Relacionamentos
- 8.4. Exemplos de Hierarquia
- 9. Split Merge
- 10. Governança do MDM
- 11. Análise da Qualidade dos Dados
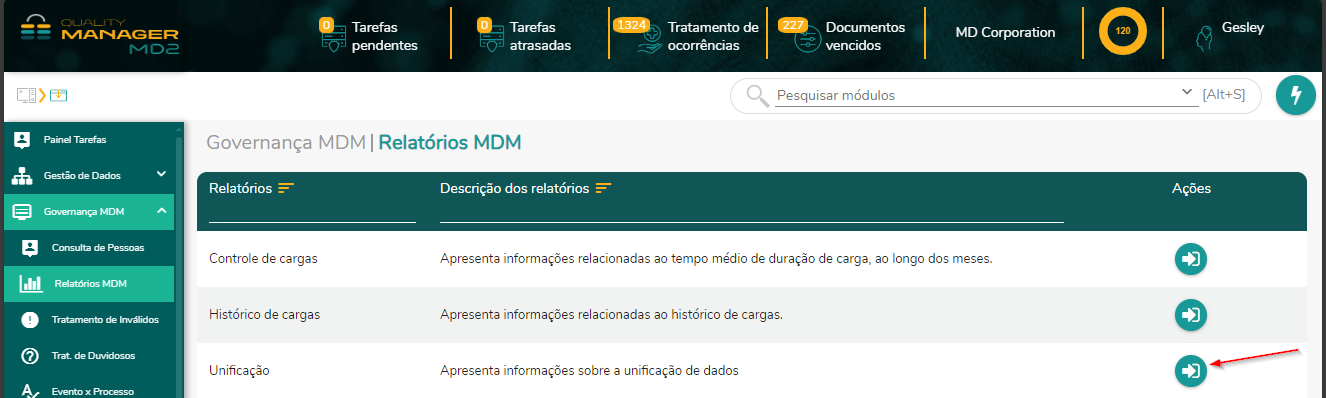
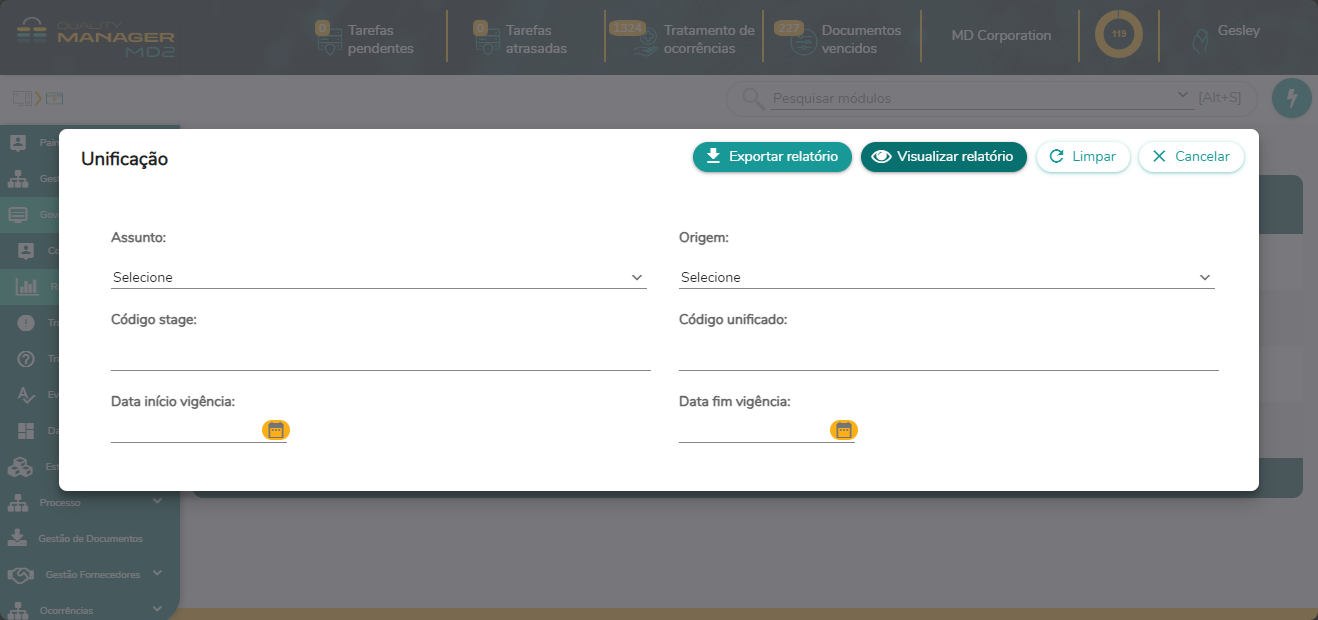
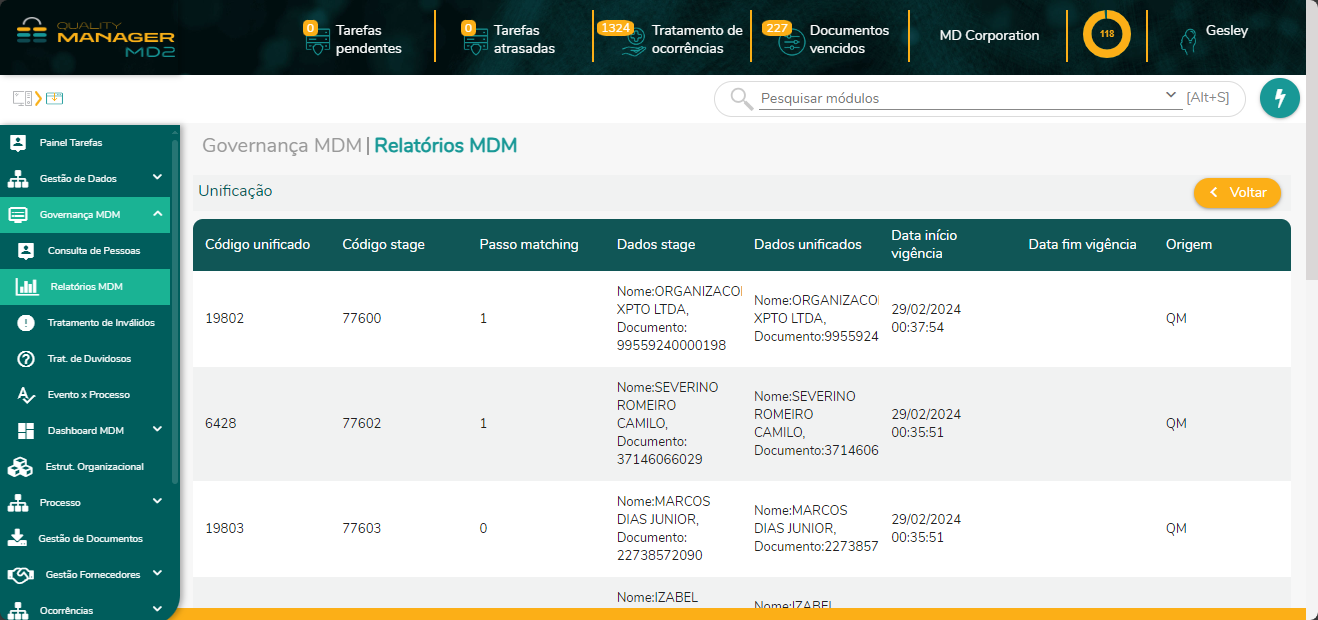
- 12. Relatórios MDM
1. Carga da Base de Referência
1.1. Carga da Base de Referências
Processos que realizam a leitura dos arquivos de BCRs e carregam os dados na Base Corporativa de Referencia (BCR). A carga dos domínios BCR ocorrem a partir dos arquivos disponibilizados como acelerador no diretório BCR/ do servidor IIS. Os arquivos listados abaixo não podem ser alterados, visto que os valores contidos nesses arquivos são usados internamente por alguns processos DataStage e pela interface do MD2 Quality Manager.
- BCR_MARCACAO_BQA_INV
- BCR_MOTIVO_INVALIDACAO
- BCR_STATUS_BQA
- BCR_STATUS_CLERICAL
- BCR_TIPO_DOCUMENTO
Os demais arquivos BCR podem ser alterados de acordo com a necessidade dos clientes. A figura abaixo apresenta um trecho da relação dos processos BCR.
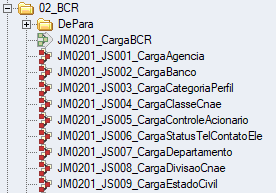
Para realizar a carga da BCR, basta executar o processo JM0201_CargaBCR. Este Job faz a chamada de todos os processos de carga das tabelas BCR, sequenciando processos que possuem integridade referencial.
O processo JM0201_CargaBCR não precisa ser executado diariamente visto que não temos atualizações frequentes nos arquivos de domínio, ou seja, este processo deverá ser executado sob demanda, quando houver alguma mudança nos arquivos utilizados na carga da BCR.
2. Controle de Carga
2.1. Controle de Carga
O controle de carga é o processo responsável por gerenciar as datas de referências (data inicial e final) de cada lote/ciclo de carga das camadas do MDM. Camada é a sequência de jobs que recebe a mesma data de referência controlada pelo controle de carga e está associada a um assunto específico dentro da solução MDM, conforme detalhado abaixo:
- STG – responsável por extrair os dados das bases origens e carregar a camada STG do modelo MDM;
- BUP – responsável por extrair os dados da STG e aplicar as regras de qualidade de dados;
- Não Unificado – responsável por carregar os registros não unificados;
- BHH – responsável por extrair os dados de endereços da BUP e associar as pessoas que compartilham um mesmo endereço;
- SplitMerge – responsável por verificar se pessoas unificadas no processo da BUP ainda devem permanecer unificadas ou devem ser separadas;
- Consentimento – responsável por ler os dados de Consentimento do MD2 Quality Manager e de outras origens e carregar as tabelas WDR;
- Enquadramento – responsável por carregar as informações de enquadramento legal, baseado nos processos formalizados no Quality Manager;
- Log Compartilhamento – responsável por ler a STG de LOG de Compartilhamento e carregar a WDR.
- Obrigação Legal – responsável por carregar as informações de obrigação legal, baseado nos processos formalizados no Quality Manager;
- Não Estruturado – responsável por realizar a consulta de dados no Stored IQ;
- Marketing – responsável por gerar o arquivo de campanha de acordo com os filtros aplicados no MD2 Quality Manager;
- Dashboard – responsável por ler as informações da STG/BUP e carregar os dados no Elastic Search;
- Ranqueamento – responsável por atuar nos assuntos MDM de Endereço, Telefone, Contato Eletrônico e Conta e
permite que os usuários possam ter uma priorização dos dados; - Grafos Relacionamento – responsável por viabilizar a visão gráfica de relacionamento da solução MD2 Master
Data Management;
O diagrama abaixo apresenta de forma macro o processo de abertura e fechamento dos lotes de processamento.

2.2. Processos de Carga Inicial
A figura abaixo apresenta a relação de processos que realizam a carga inicial das tabelas de controle de carga.
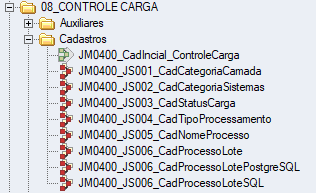
2.2.1. PROCESSO JM0400_JS001_CADCATEGORIACAMADA
Processo responsável por ler o arquivo CTR_CATEGORIA_CAMADA.csv e realizar a carga na tabela CTR_CATEGORIA_CAMADA.
2.2.2. PROCESSO JM0400_JS002_CADCATEGORIASISTEMAS
Processo responsável por ler o arquivo CTR_CATEGORIA_SISTEMA.csv, recuperar o ID da Camada e realizar a carga na tabela CTR_CATEGORIA_SISTEMA.
2.2.3. PROCESSO JM0400_JS003_CADSTATUSCARGA
Processo responsável por ler o arquivo CTR_STATUS_CARGA.csv e realizar a carga na tabela CTR_STATUS_CARGA.
2.2.4. PROCESSO JM0400_JS004_CADTIPOPROCESSAMENTO
Processo responsável por ler o arquivo CTR_TIPO_PROCESSAMENTO.csv e realizar a carga na tabela CTR_TIPO_PROCESSAMENTO.
2.2.5. PROCESSO JM0400_JS005_CADNOMEPROCESSO
Processo responsável por ler o arquivo CTR_PROCESSO.csv e realizar a carga na tabela CTR_PROCESSO.
2.2.6. PROCESSO JM0400_JS006_CADPROCESSOLOTE
Processo múltipla instância responsável por carregar a tabela CTR_PROCESSO_LOTE a partir do DSJobInvocationId e dos parâmetros DataInicialLote e DataFinalLote.
Obs.: O processo JM0400_JS006_CadProcessoLoteSQL é a versão para geração do lote em SQL Server e possui as mesmas funcionalidades detalhadas para o processo JM0400_JS006_CadProcessoLote, que é a versão para geração de lote no Oracle.
2.2.7. PROCESSO JM0400_CADINCIAL_CONTROLECARGA
Processo responsável por sequenciar os processos de carga inicial das tabelas de controle de carga. Além de carregar as tabelas cadastrais, este processo gera os lotes iniciais para cada uma das camadas do MDM, tanto em Oracle quanto SQL Server.
2.3. Processos Auxiliares
A figura abaixo apresenta a relação de processos auxiliares do controle de carga.
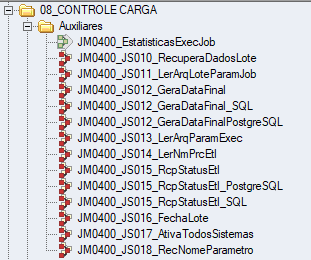
2.3.1. PROCESSO JM0400_JS010_RECUPERADADOSLOTE
Processo responsável por recuperar o último lote de execução da camada informada no parâmetro ParamCtgCamada. Caso o STA_LOTE_ABERTO_FECHADO esteja aberto (“A”), a data final do lote é atualizada para data corrente.
2.3.2. PROCESSO JM0400_JS011_LERARQLOTEPARAMJOB
Processo responsável por ler o arquivo texto gerado no job JM0400_JS010_RecuperaDadosLote de acordo com a camada informada no parâmetro ParamCtgCamada.
2.3.3. PROCESSO JM0400_JS012_GERADATAFINAL
Processo responsável por gerar as novas datas de início e fim do lote na tabela CTR_PROCESSO_LOTE de acordo com a camada informada no parâmetro ParamCtgCamada. Além disso, o processo gera o arquivo texto que será usado nos demais processos que realizam a parametrização dos Jobs.
Obs.: O processo JM0400_JS012_GeraDataFinal_SQL é a versão para geração da data final em SQL Server e possui as mesmas funcionalidades detalhadas para o processo JM0400_JS012_GeraDataFinal, que é a versão para geração de lote no Oracle.
2.3.4. PROCESSO JM0400_JS013_LERARQPARAMEXEC
Processo responsável por ler o arquivo texto gerado no job JM0400_JS012_GeraDataFinal de acordo com a camada informada no parâmetro ParamCtgCamada.
2.3.5. PROCESSO JM0400_JS016_FECHALOTE
Processo responsável por fechar o lote de execução na tabela CTR_PROCESSO_LOTE.
• Caso o processo tenha finalizado com sucesso, o campo SEQ_CTR_STATUS_CARGA é atualizado para 1 (Sucesso), o STA_LOTE_ABERTO_FECHADO para F (Fechado) e DTH_ULTIMA_ATUALIZACAO com a data e hora corrente.
• Caso o processo tenha finalizado com falha, o campo SEQ_CTR_STATUS_CARGA é atualizado para 3 (Falha), o STA_LOTE_ABERTO_FECHADO para A (Aberto) e DTH_ULTIMA_ATUALIZACAO com a data e hora corrente.
2.3.6. ESTATÍSTICAS DE EXECUÇÃO
Processos responsáveis por carregar as estáticas de execução dos processos na tabela CTR_EXECUCAO_PROCESSO.
JM0400_JS014_LerNmPrcEtl
Realiza a leitura do arquivo CTR_PROCESSO.csv, recupera o id do processo na tabela CTR_PROCESSO de acordo com o nome do processo informado no parâmetro NomeJob e salva um arquivo texto que será utilizado no Jobs subsequentes.
JM0400_JS015_RcpStatusEtl
Realiza a leitura do arquivo gerado no processo JM0400_JS014_LerNmPrcEtl de acordo com o parâmetro NomeJob e recupera a data/hora inicial, data/hora final e status de execução do processo.
Obs.: O processo JM0400_JS015_RcpStatusEtl_SQL é a versão para geração das estatísticas em SQL Server e possui as mesmas funcionalidades detalhadas para o processo JM0400_JS015_RcpStatusEtl, que é a versão para geração das estatísticas no Oracle.
JM0400_EstatisticasExecJob
Sequencer responsável por orquestrar a chamada dos processos de estatísticas de execução.
3. Extração de Dados dos Legados
Processos que leem os sistemas origens e geram arquivos com um layout padrão para cada um dos assuntos da camada STG do modelo MDM.
3.1. Estratégia de Views
3.1.1. Views
Com a intenção de simplificar o desenvolvimento de processos extratores concebemos a estratégia de extração por meio de views. O objetivo é permitir que os responsáveis pelas áreas de negócio, e suas diversas regras e lógicas, possam gerar os dados para extração, evitando dessa forma a necessidade de customizações e processos de desenvolvimento custosos para essa atividade.
A camada STG já recebe os dados como é desejado que sejam extraídos, para que então sejam processados pelo motor MDM.
As VIEWS contêm os dados para cada domínio específico da camada STG, além das informações de rastreabilidade do assunto no legado, e também a rastreabilidade com outro domínio do qual tenha dependência ou relacionamento. Exemplo: Para o assunto endereço, além dos campos de carga (logradouro, número, etc.), teremos a rastreabilidade de endereço (nome tabela e chaves do legado de endereço), além da rastreabilidade de pessoa (nome tabela e chaves do legado de pessoa), pois na camada STG, a tabela de endereço está associada à tabela de pessoa.
Abaixo a relação de Views:
| # | Tabela | Descrição | Dependência |
| 1 | VIEW_PESSOA | Dominio: VIEW que contém as informações de pessoas | Não se aplica |
| 2 | VIEW_DOCUMENTO | Dominio: VIEW que contém as informações de documento | VIEW_PESSOA |
| 3 | VIEW_ENDERECO | Dominio: VIEW que contém as informações de endereco | VIEW_PESSOA |
| 4 | VIEW_TELEFONE | Dominio: VIEW que contém as informações de telefone | VIEW_PESSOA |
| 5 | VIEW_CONTATO_ELETRONICO | Dominio: VIEW que contém as informações de contato eletronico | VIEW_PESSOA |
| 6 | VIEW_EVENTO | Dominio: VIEW que contém as informações dos eventos associados a pessoa | VIEW_PESSOA (Não obrigatório) |
| 7 | VIEW_CONTRATO | Dominio: VIEW que contém as informações de contato | VIEW_PESSOA |
| 8 | VIEW_FISCAL | Dominio: VIEW que contém as informações de fiscal | VIEW_PESSOA |
| 9 | VIEW_PERFIL | Dominio: VIEW que contém as informações de perfil | VIEW_PESSOA |
| 10 | VIEW_UNIDADE_NEGOCIO | Dominio: VIEW que contém as informações de unidade de negocio | VIEW_PESSOA |
| 11 | VIEW_CONTA | Dominio: VIEW que contém as informações de conta | VIEW_PESSOA |
| 12 | VIEW_CONTATO | Dominio: VIEW que contém as informações de contato | VIEW_PESSOA |
| 13 | VIEW_MARCACAO | Dominio: VIEW que contém as informações de marcacao | VIEW_PESSOA |
| 14 | VIEW_RELACIONAMENTO | Dominio: VIEW que contém as informações de relacionamento | VIEW_PESSOA para as duas pessoas relacionadas |
| 15 | VIEW_FUNCIONARIO | Dominio: VIEW que contém as informações de funcionario | VIEW_PESSOA para as duas pessoas relacionadas |
| 16 | VIEW_SOCIO | Dominio: VIEW que contém as informações de socio | VIEW_PESSOA para as duas pessoas relacionadas |
| 17 | VIEW_RELACAO_CONTATO_ELE | Dominio: VIEW que contém as informações da relacao contato x contato eletronico | VIEW_PESSOA, VIEW_CONTATO_ELETRONICO,VIEW_CONTATO |
| 18 | VIEW_RELACAO_CONTATO_END | Dominio: VIEW que contém as informações da relacao contato x endereco | VIEW_PESSOA, VIEW_ENDERECO,VIEW_CONTATO |
| 19 | VIEW_RELACAO_CONTATO_TEL | Dominio: VIEW que contém as informações da relacao contato x telefone | VIEW_PESSOA, VIEW_TELEFONE,VIEW_CONTATO |
| 20 | VIEW_PESSOA_INFO_ADICIONAL | Dominio: VIEW que contém as informações adicionais da pessoa | VIEW_PESSOA |
| 21 | VIEW_LOG_COMPARTILHAMENTO | Dominio: VIEW que contém as informações de registro de compartilhamento dos dados da pessoa | Não se aplica |
| 22 | VIEW_CONSENTIMENTO | Dominio: VIEW que contém as informações de registro de consentimento da pessoa | Não se aplica |
Como descrito acima, cada uma das views possuem atributos próprios pertinentes ao assunto, porém para dar maior liberdade ao cliente e permitir a inclusão de novos atributos sem a necessidade de novos desenvolvimentos, disponibilizamos no modelo, a view VIEW_PESSOA_INFO_ADICIONAL. Fazendo uso da mesma, o cliente poderá incluir quantos outros atributos desejar.
3.1.2. Cadastro de Views
Visando tornar o processo de extração de dados das Views automático, de tal forma que seja possível adicionar novas Views ao processamento sem a necessidade de desenvolver ou alterar processos, foi criada a tabela de parâmetro CTR_CADASTRO_VIEW para armazenar as informações sobre as Views, tais como, servidor, porta, nome do banco de dados, nome da conexão, nome da View.
Antes de realizar a carga na STG é necessário cadastrar as informações das origens na tabela CTR_CADASTRO_VIEW e criar as conexões com as bases de dados origem no servidor DataStage.
3.2. Camada STG
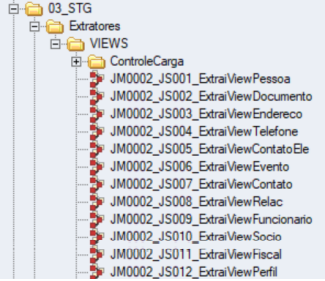
Processos responsáveis por realizar a leitura dos dados das Views e carregar os dados na camada Staging (STG). Para realizar a carga da STG, basta executar o processo 08_CONTROLECARGA\JM0400_ExecucaoViewSTG, a depender do indicador do tipo de banco de dados da base MDM.
O processo inicia a extração de dados das Views de origem executando os processos do diretório 03_STG\ Extratores\VIEWS.
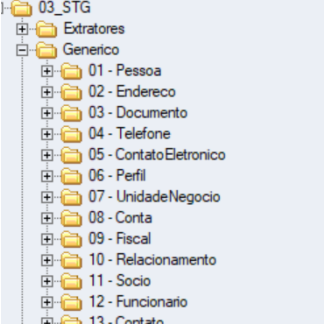
Em seguida executam os processos genéricos do diretório 03_STG\Generico, que leem os arquivos gerados nos processos
extratores e carregam as tabelas STG.
3.3. Camada BCR De-Para Domínio
Conforme é de se esperar, as empresas possuem inúmeros sistemas, alguns desenvolvidos internamente, outros adquiridos de terceiros. E consequentemente cada um desses sistemas possui uma forma de representar uma mesma informação.
- Casado, CASADO, C, c, 1, ...
- Solteiro, SOLTEIRO, S, s, 2, ....
- Divorciado, DIVORCIADO, D, d, 3, ....
- Viuvo, VIUVO, V, v, 4, ....
Com o objetivo de garantir uma padronização e criar uma visão corporativa, é preciso definir os domínios válidos. Com essa finalidade, existe na solução processos próprios com o objetivo de traduzir essas inúmeras representações para os domínios definidos nas BCRs específicas. Dessa forma é garantido que o MDM consiga interpretar a informação recebida e que a processe conforme esperado.
OBS: Os processos de De-Para de domínio serão executados sob demanda a partir do momento que a camada STG for carregada com novos sistemas ou novos domínios, ou novas traduções sejam verificados pelos responsáveis. Caso contrário, não existe a necessidade da execução desse processo.
3.4. Domínio de Classificação dos Atributos MDM
A solução MD2 MDM contempla uma camada para armazenar as informações acerca da classificação dos atributos e seus respectivos dados. Entende-se que essa é uma forma de garantir para a organização que as aplicações consumidoras dos dados mestres conheçam o domínio de classificação dos atributos MDM e dessa forma possam garantir que somente usuários com o devido perfil de acessem o dado íntegro.
O objetivo dessa camada é permitir que o administrador de dados, ou qualquer profissional responsável pelas regras de acesso aos dados, realize a classificação dos atributos do MDM de acordo com seu perfil (pessoal, sensível) e seu respectivo grau de sigilo.
Ex.: Atributo nome é classificado como Dado Pessoal, e para o grupo de acesso Especialista em Qualidade de Dados é Restrito.
4. Esteira de Qualidade de Dados
A esteira de qualidade de dados do MDM aplica regras de qualidade de dados que incluem rotinas de crítica, validação de dados e padronização de dados através de robustas regras de manipulação de Tokens, algoritmos de enriquecimento baseado em regras internas ou mesmo através de cruzamentos com bases externas como bureaus de crédito ou bases confiáveis como Correios e Anatel. Com os dados devidamente validados, padronizados e enriquecidos a esteira de qualidade do MDM segue para a etapa de resolução de identidade aplicando um mecanismo de agrupamento e correlação entre registros capaz de identificar dados que se referem a mesma pessoa. Nesta etapa de "Matching" são aplicados algoritmos de comparação probabilística com mecanismos transparentes de gestão e parametrização. Estes registros então serão logicamente interligados. Ou seja, os cadastros referentes ao mesmo indivíduo que estavam presentes na camada Integrada, poderão ser conectados a um único registro mestre em nível corporativo. Denominado "Golden Record", permitindo uma visão corporativa de todas as informações existentes sobre ela nos sistemas da empresa que estiverem conectados ao MDM.
4.1. Regras de Padronização
Processo que identifica, remove e ou corrige registros de dados imprecisos para garantir qualidade e consistência. É um processo fundamental para o gerenciamento de dados mestre (MDM).
O produto possui uma extensa biblioteca, contendo regras de padronização visando a adequação dos registros oriundos dos legados, reduzindo possíveis inconsistências que impactem nos processos de formação do golden record.
A solução também aplica a metodologia de padronização de dados da plataforma IBM, contemplando bibliotecas padrão para diversos países, inclusive o Brasil.
A MD2 enriqueceu estas rotinas com experiência de atuação de mais de 1 década implantando a solução de MDM em grandes empresas do mercado nacional e traz estes artefatos como aceleradores de projetos, além de rotinas regionalizadas e preparadas para tratar diversos tipos de dado.
Abaixo temos a tabela com algumas Regras de Padronização disponíveis:
| Nome de Recurso | Nome | Descrição Detalhada |
| Padronização Acentuação | Padronização Acentuação | Define a forma padrão de armazenamento de strings dentro do MDM, onde os caracteres devem ser persistidos sem acentuação. Os caracteres acentuados devem ser substituídos pelo caractere correspondente sem acento |
| Padronização Adequação Gênero | Padronização Adequação Gênero | Adequação dos valores de gênero para M ou F. Se os valores de gênero estiverem descritivos ou numéricos, os mesmos deverão ser convertido para M ou F |
| Padronização Agência Bancária | Padronização Agência Bancária | São retirados dígitos não numéricos. Se necessário, complementa-se o registro com zeros à esquerda até completar 4 caracteres. Caso o registro contenha 5 dígitos, tratam-se os 4 primeiros dígitos como código da agência e o 5º dígito como verificador |
| Padronização Banco | Padronização Banco | O processo insere zeros a esquerda até se atingir 3 dígitos |
| Padronização Caracteres Consecutivos | Padronização Caracteres Consecutivos | Não é permitido três ou mais caracteres iguais consecutivos conforme regra abaixo: . Não é permitido 2 caracteres iguais consecutivos no início de nomes ou sobrenomes, exceto para vogais, o excesso deve ser excluído, deixando apenas um caractere. Exemplo: Rroberto => Roberto Ssônia => Sônia Jjosé => José Ddenilson => Denilson . Não é permitido 3 ou mais caracteres iguais consecutivos no meio dos nomes ou sobrenomes, o excesso deve ser excluído, deixando apenas dois caracteres Exemplo: Barrrros => Barros Annna => Anna |
| Padronização Caracteres Consecutivos Endereço | Padronização Caracteres Consecutivos Endereço | Não é permitido três ou mais caracteres iguais consecutivos, exceto números romanos e sequência numérica . Não é permitido 2 caracteres iguais consecutivos no início de nomes ou sobrenomes, exceto para vogais, o excesso deve ser excluído, deixando apenas um caractere. Exemplo: Rroberto => Roberto Ssônia => Sônia Jjosé => José Ddenilson => Denilson . Não é permitido 3 ou mais caracteres iguais consecutivos no meio dos nomes ou sobrenomes, o excesso deve ser excluído, deixando apenas dois caracteres Exemplo: Barrrros => Barros Annna => Anna |
| Padronização Caracteres Permitidos Bairro e Cidade | Padronização Caracteres Permitidos Bairro e Cidade | Todos os caracteres devem respeitar a relação de caracteres permitidos para nome do bairro e cidade Caracteres diferentes da lista abaixo devem ser removidos: 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWZYXáàâãäÁÀÂÃÄéèêëÉÈÊËíìîïÍÌÎÏóòôõöÒÓÔÕÖúùûüÙÚÛÜýÿÝñÑçÇ" |
| Padronização Caracteres Permitidos CEP | Padronização Caracteres Permitidos CEP | Todos os caracteres devem respeitar a relação de caracteres permitidos para CEP São permitidos os caracteres numéricos 0123456789. Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos CPF | Padronização Caracteres Permitidos CPF | Todos os caracteres devem respeitar a relação de caracteres permitidos para CPF São permitidos os caracteres numéricos 0123456789. Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos Latitude e Longitude | Padronização Caracteres Permitidos Latitude e Longitude | Todos os caracteres devem respeitar a relação de caracteres permitidos para Latitude e Longitude Lista de caracteres permitidos 0123456789 .- Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos Logradouro | Padronização Caracteres Permitidos Logradouro | Todos os caracteres devem respeitar a relação de caracteres permitidos para Logradouro (Nome, Número e Complemento) Caracteres diferentes da lista abaixo devem ser removidos: 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWZYXáàâãäÁÀÂÃÄéèêëÉÈÊËíìîïÍÌÎÏóòôõöÒÓÔÕÖúùûüÙÚÛÜýÿÝñÑçÇ/-°ª,.º |
| Padronização Caracteres Permitidos Munícipio e UF IBGE | Padronização Caracteres Permitidos Munícipio e UF IBGE | Todos os caracteres devem respeitar a relação de caracteres permitidos para município e UF IBGE São permitidos os caracteres numéricos 0123456789. Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos para E-mail | Padronização Caracteres Permitidos para E-mail | Todos os caracteres devem respeitar a relação de caracteres permitidos para E-mail São permitidos os caracteres alfabéticos abcdefghijklmnopqrstuvwxyz , numéricos 0123456789 e também os especiais . _ - @ Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos para Nome do País | Padronização Caracteres Permitidos para Nome do País | Todos os caracteres devem respeitar a relação de caracteres permitidos para nome do país Caracteres diferentes da lista abaixo devem ser removidos: " 0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWZYXáàâãäÁÀÂÃÄéèêëÉÈÊËíìîïÍÌÎÏóòôõöÒÓÔÕÖúùûüÙÚÛÜýÿÝñÑçÇ" |
| Padronização Caracteres Permitidos para Nome Pessoa Física | Padronização Caracteres Permitidos para Nome Pessoa Física | Todos os caracteres devem respeitar a relação de caracteres permitidos para nome de Pessoa Física Caracteres diferentes da lista abaixo devem ser removidos: " ABCDEFGHIJKLMNOPQRSTUVWXYZ" |
| Padronização Caracteres Permitidos para Telefone | Padronização Caracteres Permitidos para Telefone | Todos os caracteres devem respeitar a relação de caracteres permitidos para Telefone (DDI, DDD, Telefone e Ramal) São permitidos os caracteres numéricos 0123456789. Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos RG e Passaporte | Padronização Caracteres Permitidos RG e Passaporte | Todos os caracteres devem respeitar a relação de caracteres permitidos para RG e Passaporte São permitidos os caracteres numéricos 0123456789 e alfabéticos ABCDEFGHIJKLMNOPQRSTUVXWYZ Caracteres diferentes desta lista devem ser removidos. |
| Padronização Caracteres Permitidos UF | Padronização Caracteres Permitidos UF | Todos os caracteres devem respeitar a relação de caracteres permitidos para UF Caracteres diferentes da lista abaixo devem ser removidos: ABCDEFGHIJKLMNOPQRSTUVWXYZ |
| Padronização Case Sensitive | Padronização Case Sensitive | Define a forma padrão de armazenamento de strings dentro do MDM, onde os caracteres devem ser persistidos em caixa alta (maiúsculas) |
| Padronização Case Sensitive E-mail | Padronização Case Sensitive E-mail | Define a forma padrão de armazenamento de strings de e-mail dentro do MDM, onde os caracteres devem ser persistidos em caixa baixa (minúsculas) |
| Padronização CEP Genéricos | Padronização CEP Genéricos | Não é permitido a existência de conteúdo genérico de CEP. Se conteúdo genérico, inferir nulo Ex: 00000000, 11111111 ... 99999999 |
| Padronização Complemento CEP de São Paulo | Padronização Complemento CEP de São Paulo | Complemento com zero a esquerda para CEP de São Paulo. Concatenar um zero a esquerda quando a UF='SP' e o CEP contiver 7 dígitos |
| Padronização Complemento Logradouro | Padronização Complemento Logradouro | Padronização informações de complemento de logradouro escritas de formas distintas ou inválidas Quando iniciar com SL e logo após a letra possuir espaço, substituir por "SALA" Quando iniciar com S e após o espaço a direita houver um caracter diferente da letra N , substituir por "SALA" Quando campos possuir SN, S/N, S N, remover da string |
| Padronização Complemento Zero a Esquerda CPF | Padronização Complemento Zero a Esquerda CPF | Complementar com zero a esquerda do CPF quando conteúdo for inferior a 11 dígitos. Quando o CPF possuir quantidade inferior a 11 dígitos, incluir zeros a esquerda completando o número em 11 dígitos |
| Padronização Completude Sufixo e Prefixo Nome Pessoa Física | Padronização Completude Sufixo e Prefixo Nome Pessoa Física | Aplicar rotina QualityStage de padronização de nomes para completude de sufixo e prefixo do nome, corrigindo as principais abreviaturas e movendo o prefixo do nome para nome de tratamento Exemplo: "DR. JOAO DA SILVA JR" -> "JOAO DA SILVA JUNIOR" , o prefixo DR. será movido para o campo de nome de tratamento |
| Padronização Conteúdo SN | Padronização Conteúdo SN | Padronização informação "Sem Número" escrita de formas distintas. Quando conteúdo contiver “SNUMERO, SN, S N,S/NUMERO, SN, S/N, S N, S/NR, SNR” entre espaços, substituir a string por "S/N" |
| Padronização Correção Abreviações Bairro | Padronização Correção Abreviações Bairro | Correção de abreviações comuns para nome do bairro. Substituir: . Z. ou Z por Zona . VL V.L. VL. V.L maiúsculas ou minúsculas por VILA . STA STA. STª Sta maiúsculas ou minúsculas por SANTA . RS RES RES. Res. Res por RESIDENCIAL . PRQ PQUE Pque PQ PQ. Pq Pq. por PARQUE . JD. JD Jdim JDIM Jd Jd. por Jardim . Dist. Dist Distr. DISTR DIS DIS. Dis Dis. por DISTRITO . CPO por CAMPO . COND COND. por CONDOMINIO Aplicar rotina QualityStage para completude e padronização da informação do nome do bairro |
| Padronização Correção Provedores de E-mail | Padronização Correção Provedores de E-mail | Completude e padronização da informação de e-mail para tradução de erros comuns de provedores de e-mail Exemplo gmael -> gmail gmai -> gmail hgotmail -> hotmail hhotmail -> hotmail Acerto no final do e-mail onde após o provedor não existir ".com",".com.br", "br" |
| Padronização Corrreção Erros Comuns Final E-mail | Padronização Corrreção Erros Comuns Final E-mail | Correção dos erros comuns no final da string de E-mail Exemplo: "com.ltda" -> ".com.br" "comm.br" -> ".com.br" ".cvom.br" -> ".com.br" |
| Padronização Data Nascimento Inconsistente | Padronização Data Nascimento Inconsistente | Os valores contidos na data de nascimento devem ser consistentes, ou seja, devem possuir um intervalo de valores mínimo e máximo. Valores superiores a data atual e inferiores a 1900-01-01 devem ser anulados |
| Padronização Data Óbito Inconsistente | Padronização Data Óbito Inconsistente | Os valores contidos na data de óbito devem ser consistentes, ou seja, devem possuir um intervalo de valores mínimo e máximo. Valores superiores a data atual , inferiores a 1900-01-01 ou inferiores a data de nascimento devem ser anulados |
| Padronização Espaçamento de Strings | Padronização Espaçamento de Strings | Define a forma padrão de espaçamento de strings. O excesso de espaçamento deve ser removido. Espaço no início ou no final da string também deve ser removido, exemplo: " JOAO DA SILVA SOARES " -> "JOAO DA SILVA SOARES" |
| Padronização Formato de Data | Padronização Formato de Data | As datas devem ser armazenadas seguindo um formato padrão. Armazenar no HUB MDM as datas no formato: YYYY-MM-DD HH:MM:SS |
| Padronização Inclusão de Dígitos | Padronização Inclusão de Dígitos | Inclusão do nono dígito para telefone celular e dígito três para telefone fixo Se possuir oito dígitos e Iniciado por 6, 7, 8 ou 9: . Incluir o 9 a esquerda do número do telefone para telefones que não sejam NEXTEL conforme tabela ANATEL Se possuir sete dígitos e o campo tiver data de alteração/inclusão anterior ao ano de 2006, incluir o número 3 no início do número |
| Padronização Quantidade Máxima de Caracteres Número Logradouro | Padronização Quantidade Máxima de Caracteres Número Logradouro | O número de logradouro não deve ser maior que 14 caracteres. Caso ultrapasse o valor máximo, o conteúdo do número do logradouro deverá ser anulado |
| Padronização Quantidade Máxima de Números Ramal | Padronização Quantidade Máxima de Números Ramal | O número do ramal deve respeitar a quantidade máxima de caracteres. Os valores que não respeitarem essa restrição deverão ser anulados |
| Padronização Quantidade Mínima de Caracteres Bairro | Padronização Quantidade Mínima de Caracteres Bairro | O nome do bairro não deve ser menor que 2 caracteres. Caso seja inferior ao valor mínimo, o conteúdo do nome do bairro deverá ser anulado |
| Padronização Quantidade Mínima de Caracteres Complemento Logradouro | Padronização Quantidade Mínima de Caracteres Complemento Logradouro | O complemento de logradouro não deve ser menor que 2 caracteres. Caso seja inferior ao valor mínimo, o conteúdo do complemento do logradouro deverá ser anulado |
| Padronização Remoção Caracteres Indesejados E-mail | Padronização Remoção Caracteres Indesejados E-mail | Não é permitido a existência de determinados caracteres antes e após o @ e caracteres especiais em sequencia. Conforme relação abaixo, devemos substituir : @@ por @ -@ por @ @- por @ .@ por @ @. por @ _@ por @ @_ por @ -- por - .. por . |
| Padronização Remoção de Dígitos | Padronização Remoção de Dígitos | Remover zeros a esquerda do Telefone, DDD e DDI |
| Padronização Remoção Espaço E-mail | Padronização Remoção Espaço E-mail | Não é permitido espaços em branco na string de e-mail. Os espaços entre strings, no início e no final da string devem ser removidos |
| Padronização Remoção Palavra Indesejada para Nome Cidade | Padronização Remoção Palavra Indesejada para Nome Cidade | Palavras indesejadas devem ser removidas do conteúdo Nome Cidade Possuindo a palavra Capital no final da string, a mesma deverá ser excluída. Exemplo: Rio de Janeiro Capital - > Rio de Janeiro Possuindo a string 'N D' , substituir por nulo |
| Padronização Remoção Pontuação no Início e Final da String | Padronização Remoção Pontuação no Início e Final da String | A string de e-mail não pode iniciar ou terminar com caractere .(ponto). Os pontos no início e no final da string devem ser removidos, caso existam |
| Padronização Remoção String Indesejada E-mail | Padronização Remoção String Indesejada E-mail | Remover do conteúdo a string "e-mail:" Exemplo: "e-mail: joaodasilva@email.com.br" -> "joaodasilva@email.com.br" |
| Padronização Remoção String Indesejada Nome Logradouro | Padronização Remoção String Indesejada Nome Logradouro | Strings indesejadas devem ser removidas do conteúdo Nome Logradouro Quando conteúdo contiver “S/NUMERO, SN, S/N, S N, S/NR, SNR” entre espaços, remover da string |
| Padronização Remoção Zero a Esquerda CEP | Padronização Remoção Zero a Esquerda CEP | Remoção zero a esquerda do CEP caso contenha 9 dígitos e o primeiro dígito for zero |
| Padronização Separação Conteúdo Nome Logradouro | Padronização Separação Conteúdo Nome Logradouro | Separação Tipo, Número e Complemento Logradouro do Nome Logradouro Aplicar rotina QualityStage para completude e padronização da informação do nome do logradouro , tipo de logradouro, número do logradouro e complemento, separando as informações caso estejam presentes na string de Nome Logradouro |
| Padronização Separação Conteúdo Número Logradouro | Padronização Separação Conteúdo Número Logradouro | Separação Complemento Logradouro do Número Logradouro. Quando número do logradouro iniciar com AP, APTO ou APT e houver números após esses caracteres, remover da string Quando número do logradouro iniciar com AP, APTO ou APT e houver números após esses caracteres, retirar do campo “número” e acrescentar ao campo complemento sem excluir o que já existe nesse campo. Se a informação retirada no campo “número” for igual a presente no campo “complemento”, descartar informação Quando número do logradouro iniciar com número da esquerda para a direita e após esses tiver AP, APTO, APT, CASA ou CS e houver números da esquerda para a direita após esses caracteres, remover todo o conteúdo da string após o primeiro número Ex: 123 AP 456 -> 123 permaneceria em número logradouro e AP 456 seria migrado para complemento logradouro |
| Padronização Separação de E-mail | Padronização Separação de E-mail | Separa as ocorrências de vários e-mails em uma mesma string a partir dos caracteres delimitadores "/\ >< , ; # - ". Os dados entre eles devem ser quebrados em linhas para análise e tratamento unitário |
| Padronização Separação de Telefone | Padronização Separação de Telefone | Separa as ocorrências de vários telefones em uma mesma string a partir das seguintes regras: Quando possuir os caracteres delimitadores " ; / OU ", eliminar o caractere delimitador, separando o conteúdo de telefone em linhas distintas. Exemplo: 32227856ou991913455 32227856;991913455 , ficará: 32227856 991913455 32227856 991913455, sendo cada número de telefone um novo registro Para campos com 15 caracteres, somente numéricos, dividi-los em duas partes (8 dígitos e 7 dígitos), separando em linhas distintas de telefone. Para campos com 16 caracteres, somente numéricos, dividi-los em duas partes iguais com 8 caracteres cada em linhas distintas de telefone. |
| Padronização Separação Município da UF IBGE | Padronização Separação Município da UF IBGE | Separação Município da UF IBGE quando o conteúdo estiver em uma mesma string Realizar a separação do código da UF e do município nos casos em que o campo “código UF IBGE” contem 7 dígitos. E o "código município IBGE" não contenha conteúdo Recuperar os dois primeiros dígitos para código UF IBGE Recuperar os 5 últimos dígitos para código município IBGE |
| Padronização Separação RG, UF e Órgão Emissor | Padronização Separação RG, UF e Órgão Emissor | Separa o número RG, UF e Órgão Emissor contidos em uma mesma string Exemplo: MG 102030 SSP -> MG (UF Emissor), 102030 (Número RG), SSP (Órgão Emissor) |
| Padronização Separação UF do Nome Cidade | Padronização Separação UF do Nome Cidade | Separação da UF do Nome da Cidade quando o conteúdo contiver as duas informações A separação da UF deve ocorrer a partir da aplicação da regra abaixo: Se o terceiro caractere for traço “-“ ou barra “/”(desconsiderando os espaços) e a direita dele possuir dois caracteres alfabéticos, remover traço “-“ ou barra “/” . Os dois caracteres posteriores serão removidos do Nome da Cidade e movidos para UF Ex: São Paulo - SP -> Cidade ficaria com o conteúdo "São Paulo" e UF ficaria com o conteúdo "SP" |
| Padronização Substituição Dígito Dois ou Caractere Asterico por Arroba | Padronização Substituição Dígito Dois ou Caractere Asterico por Arroba | Substituir o dígito 2 pelo caractere @ quando: O conteúdo do campo e-mail conter somente uma ocorrência do número 2 e o campo e-mail não possuir @ Substituir o caractere * pelo caractere @ quando: O conteúdo do campo e-mail conter somente uma ocorrência do * e o campo e-mail não possuir @ |
| Padronização Tamanho Padrão de Caracteres CEP | Padronização Tamanho Padrão de Caracteres CEP | Os valores de CEP devem respeitar o tamanho padrão de 8 dígitos numéricos. Se quantidade de dígitos do CEP for diferente de 8, inferir Nulo |
| Padronização Tamanho Padrão PIS/PASEP/NIT | Padronização Tamanho Padrão PIS/PASEP/NIT | Define o tamanho padrão de 11 dígitos para armazenamento das informações de PIS/PASEP/NIT Campos inferiores a 11 caracteres, completar com zero a esquerda |
| Padronização Tradução Nome Cidade | Padronização Tradução Nome Cidade | Tradução das abreviações e correção de erros comuns de digitação do Nome Cidade Aplicar rotina QualityStage para tradução das abreviações e correção de erros comuns de digitação do Nome Cidade Exemplo: BH -> BELO HORIZONTE MOJIMIRIM -> MOGI MIRIM |
| Padronização Validação Bairro DNE | Padronização Validação Bairro DNE | Efetuar validação conjunta da UF, CIDADE, BAIRRO com a tabela DNE_BAIRRO dos Correios. Para as informações que não forem consistentes, aplicar rotina QualityStage de matching para comparação aproximada do BAIRRO com a tabela DNE_BAIRRO dos Correios |
| Padronização Validação Cidade DNE | Padronização Validação Cidade DNE | Efetuar validação da UF e CIDADE com a tabela DNE_CIDADE dos Correios. Para as informações que não forem consistentes, aplicar rotina QualityStage de matching para comparação aproximada da CIDADE com a tabela DNE_CIDADE dos Correios |
| Padronização Validação DDD Anatel | Padronização Validação DDD Anatel | Verificar se o DDD é válido na Anatel. Caso os valores não sejam válidos, os mesmos deverão ser anulados |
| Padronização Validação DDI Anatel | Padronização Validação DDI Anatel | Verificar se o DDI é válido na Anatel. Caso os valores não sejam válidos, os mesmos deverão ser anulados |
| Padronização Validação Nome Logradouro DNE | Padronização Validação Nome Logradouro DNE | Efetuar validação conjunta da UF, CIDADE, BAIRRO e NOME LOGRADOURO com a tabela DNE_LOGRADOURO dos Correios. Para as informações que não forem consistentes, aplicar rotina QualityStage de matching para comparação aproximada do NOME LOGRADOURO com a tabela DNE_LOGRADOURO dos Correios |
| Padronização Validação Nome País DNE | Padronização Validação Nome País DNE | Realizar a validação do Nome do País com a tabela DNE_PAIS. Informações que não forem consistentes deve-se inferir Nulo no campo |
| Padronização Validação Prefixo Telefone e DDD Anatel | Padronização Validação Prefixo Telefone e DDD Anatel | Verificar se o prefixo do Telefone e DDD são válidos na Anatel a) Para telefones celulares (primeiro digito=9), devemos pegar os 5 primeiros dígitos como prefixo b) Para telefone fixo (primeiro digito 2, 3, 4 ou 5 ), pegar os 4 primeiros dígitos como prefixo Validar o DDD e PREFIXO com a tabela BCR_PREFIXO_ANATEL através dos campos NUMERO_DDD e NUMERO_PREFIXO. |
| Padronização Validação Tipo Logradouro DNE | Padronização Validação Tipo Logradouro DNE | Efetuar validação do Tipo de Logradouro com o DNE dos Correios. Validar campo descritivo tipo logradouro na tabela de dominio DNE_TIPO_LOGRADOURO, inferir nulo caso não seja válido |
| Padronização Validação UF DNE | Padronização Validação UF DNE | Efetuar validação do campo UF com a tabela DNE_UF dos Correios, as informações que não forem consistentes, inferir Nulo |
4.2. Enriquecimento de Dados
Enriquecimento de dados refere-se a processos usados para aprimorar, refinar ou melhorar os dados. No mundo do MDM, o enriquecimento de seus dados mestres pode acontecer pela inclusão de dados de terceiros para obter uma visão mais completa, por exemplo.
O MD2 MDM aplica diversas técnicas de enriquecimento de dados evoluídas a partir da larga experiência na implementação de soluções robustas nesse contexto em diversas empresas do âmbito nacional. As técnicas podem ser classificadas como atômicas, regras internas ou mesmo consulta a bases externas de referência.
Exemplos de regras de enriquecimento de dados:
Atômica:
- Inferência de Gênero pelo Nome
- Eliminação de Duplo @@ em e-mails
Internas:
- Ajustes de Domínios de Dados Corporativos (De-Para de Domínios)
- Regras de Negócio ou Bases Internas de Referência
Externas
- Validação de Titularidade de Documentos (em Bureaus Externos)
- Enriquecimento de Endereços baseado no DNE (Diretório Nacional de Endereçamento Postal)
Exemplificando esse tópico, abaixo uma tabela com as regras de enriquecimento de dados referentes ao DNE implementadas em nossa solução:
| Nome de Recurso | Nome | Descrição Detalhada |
| Enriquecimento Bairro DNE | Enriquecimento Bairro DNE | Enriquecimento do Bairro a partir do número do CEP considerando a seguinte regra: Se campo Bairro não estiver preenchido, recuperar o Bairro pelo intervalo de CEP usando as tabelas do DNE para bairros pertencentes a cidades que não possuem CEP único |
| Enriquecimento CEP DNE | Enriquecimento CEP DNE | Enriquecimento do CEP a partir da UF, Cidade, Bairro e Logradouro considerando a seguinte regra: Se campo CEP não estiver preenchido, recuperar o CEP através da UF, Cidade, Bairro e Logradouro usando as tabelas do DNE para cidades que não possuem CEP Único Se campo CEP não estiver preenchido e Cidade com CEP único, recuperar CEP da tabela DNE_CIDADE |
| Enriquecimento Cidade DNE | Enriquecimento Cidade DNE | Enriquecimento da Cidade a partir do número do CEP considerando a seguinte regra: Se campo Cidade não estiver preenchida, recuperar a Cidade pelo intervalo de CEP usando as tabelas do DNE Para Cidades com CEP único, se Cidade não estiver preenchida, recuperar a Cidade pelo CEP usando a tabela DNE_CIDADE |
| Enriquecimento DDD | Enriquecimento DDD | Enriquecimento do DDD a partir do número do telefone considerando a seguinte regra: . Número do telefone contendo dez caracteres, verificar se os dois primeiros caracteres da esquerda para a direita se enquadram da relação da Anatel dos códigos de Discagem Direta a Distância, caso positivo, separa-los no campo DDD, e os 8 caracteres restantes permanecerão no campo número do telefone . Número do telefone contendo onze caracteres verificar se os dois primeiros caracteres da esquerda para a direita se enquadram da relação da Anatel dos códigos de Discagem Direta a Distância, caso positivo, separa-los no campo DDD, e os 9 caracteres restantes permanecerão no campo número do telefone |
| Enriquecimento DDI | Enriquecimento DDI | Enriquecimento do DDI a partir da validação dos dados na Anatel Quando os campos DDD e Telefone estiverem preenchidos e válidos na Anatel, preencher automaticamente o DDI do Brasil (55). |
| Enriquecimento Gênero | Enriquecimento Gênero | Enriquecimento do Gênero a partir do nome da pessoa utilizando a regra de padronização do QualityStage que possui a lista com o de-para nome x gênero. O enriquecimento só deverá ocorrer se o Gênero estiver sem conteúdo e a regra de padronização QualityStage efetuar a geração do Gênero a partir do nome |
| Enriquecimento Logradouro DNE | Enriquecimento Logradouro DNE | Enriquecimento do Nome Logradouro a partir do número do CEP considerando a seguinte regra: Se campo Logradouro não estiver preenchido, recuperar o Logradouro pelo CEP usando as tabelas do DNE |
| Enriquecimento Nacionalidade | Enriquecimento Nacionalidade | Enriquecimento da Nacionalidade com a string "BR" quando a Nacionalidade não estiver preenchida e os dados de UF ou Nome da Cidade forem válidos no DNE |
| Enriquecimento UF Cidade DNE | Enriquecimento UF Cidade DNE | Enriquecimento da UF a partir do nome da cidade do DNE Correios Quando a UF não estiver preenchida, recuperar a UF da tabela DNE_CIDADE a partir do nome da cidade. O enriquecimento deverá ser realizado somente quando o nome da cidade for exclusivo para uma única UF em todo o Brasil |
| Enriquecimento UF DNE | Enriquecimento UF DNE | Enriquecimento da UF a partir do número do CEP considerando a seguinte regra: Se campo UF não estiver preenchido, recuperar a UF a pelo intervalo de CEP usando as tabelas do DNE |
A solução parte do pressuposto que o enriquecimento garante dados mais confiáveis e fidedignos, auxiliando por consequência em todo processo de construção do Golden Record. Por meio de sua arquitetura, incluindo processos e modelo de dados, possibilita-se a adequação visando a utilização de diversas técnicas para enriquecer os dados.
4.3. Crítica de Dados
Os registros provenientes dos sistemas legados podem estar repletos de anomalias. Os motivos podem ser adversos, inclusive detectados em tempo de projeto. É preciso criar estruturas rígidas de críticas e filtros das informações da origem, para que sua entrada no MDM seja autorizada. Caso contrário estes problemas serão migrados para a base qualificada, afetando sua utilização estratégica.
Nesta etapa, é necessário aplicar as regras de crítica e validação da informação com objetivo de estabelecer critérios de qualidade para que a informação possa ser persistida no MDM. Alguns exemplos de regras de crítica:
- Nome de Pessoa Física deve conter mais que uma palavra;
- Nome de Pessoa Física não pode conter palavrões;
- CPF, CNPJ, CNH devem possuir o dígito verificador válido;
- O E-mail deve possuir sintaxe válida;
- O Telefone não pode conter mais que onze dígitos.
Abaixo temos a tabela com as Críticas de Dados:
| Nome de Recurso | Nome | Descrição Detalhada |
| Crítica CNH | Crítica CNH | A crítica de CNH segue as seguintes regras: 1- Verificação de tamanho da CNH, sendo 9 dígitos validamos de acordo com os padrões da CNH Antiga, sendo 11 dígitos validamos conforme os padrões da CNH nova 2- Verifica se todos dígitos são numéricos 3- Verifica se o documento não é viciado. 4- Valida-se dígito verificador Como adendo, caso a categoria da CNH seja inválida cria-se um alerta, porém caso o CNH seja válido o dado é somado ao Golden Record |
| Crítica CTPS | Crítica CTPS | A crítica de CTPS invalida um registro nos casos em que: 1- O número de série tiver tamanho maior que 5 dígitos 2- O número do documento tiver tamanho maior que 8 dígitos 3- O número do documento estiver viciado |
| Crítica DDD e DDI Nulo | Crítica DDD e DDI Nulo | Gerar alerta se o número do DDD ou DDI possuírem conteúdo nulo, vazio ou somente espaços em branco |
| Crítica Documento com Vício Preenchimento | Crítica Documento com Vício Preenchimento | O número do documento não pode conter vício de preenchimento. O número do documento não pode conter vício de preenchimento, ou seja, não pode conter a repetição de um mesmo caractere em todo o conteúdo da string Exemplo: XXXXX,ZZZZZ,11111,22222 Os registros que não respeitarem essa restrição deverão ser invalidados |
| Crítica E-mail com Vício de Preenchimento | Crítica E-mail com Vício de Preenchimento | O e-mail não pode conter vício de preenchimento, ou seja, não pode conter a repetição de um mesmo caractere em todo o conteúdo da string Exemplo: XXXXX,ZZZZZ |
| Crítica E-mail Fora do Padrão | Crítica E-mail Fora do Padrão | Os e-mails devem obedecer uma estrutura padrão de conteúdo, conforme regra abaixo: • À esquerda do @: . O primeiro caractere deve ser alfanuméricos abcdefghijklmnopqrstuvwxyz ou 0123456789 . Ex: Exemplo: maria-rossi@hotmail.com ,maria-rossi2000@hotmail.com, 123maria@hotmail.com .É obrigatório conter pelo menos um caractere alfabético • À direita do @: . Deve haver no mínimo dois caracteres alfanuméricos abcdefghijklmnopqrstuvwxyz 0123456789 . Não é permitido iniciar com caractere diferente dos alfanuméricos Ex: nmneto@.md2.com.br (não permitido) . Não é permitida a finalização com qualquer caractere diferente do alfabético abcdefghijklmnopqrstuvwxyz Ex: nmneto@md2.com.br.. (não permitido) nmneto@md2.com.br1 (não permitido) . Deve possuir pelo menos um ponto e no máximo 3 pontos. . Entre ou após os pontos deve conter no mínimo dois caracteres alfanuméricos . Não é permitido dois ou mais pontos sequenciais, Ex: nmneto@md2..com.br => (não permitido) Ex. permitido: Ex. não permitido xpto@r7.br xpto@_r1.com xpto@r-7.aaa.com.br xpto@r7.aa-.a xpto@r_7.us xpto@aa-.a_.aa Os registros que violarem o formato padrão deverão ser invalidados |
| Crítica Email Genérico | Crítica Email Genérico | O e-mail não pode conter valores genéricos Aplicar rotina QualityStage para completude e padronização da informação de e-mail para identificação de e-mails genéricos mais comuns. Exemplo: clientenaopossui clientenaopossuiem clientenaotem clientenaotememail naopossuiemail naopossuiemailpessoal Os registros identificados como e-mails genéricos deverão ser invalidados |
| Crítica Endereço Nulo | Crítica Endereço Nulo | As informações de endereço devem estar preenchidas Pelo menos um dos campos de endereço, tais como nome do logradouro, bairro, cidade ou CEP devem estar preenchidos. Os registros que não respeitarem essa restrição deverão ser invalidados. |
| Crítica Estrutura Padrão Passaporte | Crítica Estrutura Padrão Passaporte | Os valores de Passaporte devem respeitar a estrutura padrão. Campo composto por no máximo 11 algarismos, composto por números e letras, porém é permitido letras antes e após os números, não podendo possuir letras entre os números Ex. não permitido: W123456AB789 Ex. permitido: W123456Z Registros que não atenderem a regra estrutural, deverão ser invalidados |
| Crítica Estrutura Padrão RG | Crítica Estrutura Padrão RG | Os valores de RG de estados diferente de RJ e SP devem respeitar o tamanho padrão entre 2 e 11 dígitos. Para os estados de RJ e SP o tamanho permitido é de 9 caracteres e ainda é utilizado uma regra que valida o dígito verificador.Será gerando uma alerta para registros que não atenderem essa condição |
| Crítica Nome Blocklist | Crítica Nome Blocklist | O nome não pode conter palavras existentes na blocklist de nomes. A blocklist de nomes contém uma relação de palavrões e xingamentos que podem estar ocultos no nome da pessoa. Os registros que não respeitarem essa restrição deverão ser invalidados. |
| Crítica Nome com Vício de Preenchimento | Crítica Nome com Vício de Preenchimento | O nome da Pessoa Física ou Jurídica não pode conter vício de preenchimento, ou seja, não pode conter a repetição de um mesmo caractere em todo o conteúdo da string Exemplo: XXXXX, ZZZZZ Os registros que não respeitarem essa restrição deverão ser invalidados |
| Crítica Nome Nulo | Crítica Nome Nulo | O nome da Pessoa Física ou Jurídica deve estar preenchido O nome da Pessoa Física ou Jurídica não pode ser nulo, vazio ou somente espaços em branco. Os registros que não respeitarem essa restrição deverão ser invalidados. |
| Crítica Nome Pai e Mãe com Vício de Preenchimento | Crítica Nome Pai e Mãe com Vício de Preenchimento | O nome do Pai e Mãe não pode conter vício de preenchimento, ou seja, o não pode conter a repetição de um mesmo caractere em todo o conteúdo da string Exemplo: XXXXX, ZZZZZ Os nomes de Pai e Mãe que não respeitarem essa restrição deverão ser anulados |
| Crítica Nome Pai e Mãe na Blocklist | Crítica Nome Pai e Mãe na Blocklist | O nome do Pai e Mãe não pode conter palavras existentes na blocklist de nomes. A blocklist de nomes contém uma relação de palavrões e xingamentos que podem estar ocultos no nome da pessoa. Os nomes que não respeitarem essa restrição deverão ser anulados e um alerta será gerado informando essa situação |
| Crítica Pessoas Diferentes Com o Mesmo CPF | Crítica Pessoas Diferentes Com o Mesmo CPF | O CPF não pode estar associado a mais de uma pessoa. Caso contrario, o registro deverá ser invalidado |
| Crítica Quantidade Mínima de Caracteres Nome Pai e Mãe | Crítica Quantidade Mínima de Caracteres Nome Pai e Mãe | O nome do Pai e Mãe deve respeitar a quantidade mínima de 3 caracteres. Os nomes que não respeitarem essa restrição deverão ser anulados e um alerta será gerado informando essa situação |
| Crítica Quantidade Mínima de Palavras Nome Pessoa Física | Crítica Quantidade Mínima de Palavras Nome Pessoa Física | O nome de Pessoa Física deve respeitar a quantidade mínima de palavras Os registros com Nome de Pessoa Física que não respeitarem as regras abaixo deverão ser invalidados: Nome com apenas uma palavra Nome com duas palavras, com um caractere em um das palavras |
| Crítica Telefone com Vício de Preenchimento | Crítica Telefone com Vício de Preenchimento | O número do telefone não pode conter vício de preenchimento, ou seja, não pode conter a repetição de um mesmo caractere em todo o conteúdo da string Exemplo: 11111,22222 Os registros que não respeitarem essa restrição deverão ser invalidados |
| Crítica Telefone Fora do Padrão | Crítica Telefone Fora do Padrão | Os telefones devem obedecer uma estrutura padrão de conteúdo, conforme regra abaixo: Telefones devem respeitar a seguinte regra estrutural: Fixo: deve conter 8 caracteres numéricos e iniciados (da esquerda para a direita) pelos números 2 (dois), 3 (três), 4 (quatro) ou 5 (cinco); Móvel:deve conter 9 caracteres numéricos iniciados pelo número 9 Especial: iniciar com 0800 e possuir até 11 números Os registros que violarem o formato padrão deverão ser invalidados |
| Crítica Telefone Nulo | Crítica Telefone Nulo | O número do telefone não pode ser nulo, vazio ou somente espaços em branco. Os registros que não respeitarem essa restrição deverão ser descartados. |
| Crítica Validação CPF | Crítica Validação CPF | Validação CPF pelo dígito verificador. Caso documento não seja válido , o registro deverá ser invalidado |
| Crítica Validação PIS | Crítica Validação PIS | Validação PIS pelo dígito verificador. Caso documento não seja válido , o registro deverá ser invalidado |
4.4. Matching
Uma vez os dados padronizados, criticados e muitas vezes enriquecidos chega-se ao momento em que deve-se comparar e agrupar os registros que se correspondem. Para fazer essa comparação ou matching, o processo calcula a probabilidade de um registro estar relacionado a outro. Ele envolve uma configuração de quão semelhantes são os registros, usando limiares (limites). Os limites definem qual o valor necessário para que os registros sejam considerados duplicados ou não.
Através dessas regras, é possível realizar uma comparação probabilística e estabelecer notas para validar se duas ou mais ocorrências se tratam de um mesmo registro, mesmo que possuam divergências entre si, como por exemplo Igor, Ygor ou Higor. A solução leva em consideração muito mais do que apenas o NOME, pois é possível unificar homónimos, nem apenas o CPF pois pode-se unificar irmãos ou marido e mulher que compartilharam daquele documento, situações essas bastante comuns encontradas nos sistemas.
Para serem mais assertivos, as regras de matching/comparações, aplicadas na solução MD2 MDM são mais inteligentes e robustas, possuindo inúmeros passos, com diferentes regras que foram sendo desenvolvidas e melhoradas durante anos de prática nos inúmeros projetos entregues. A cada nova release essas regras podem ser revisadas pela equipe de desenvolvimento que estão constantemente revisando e melhorando os motores de qualidade.
Uma vez feita essa comparação, cada registro é agrupado com seus similares e ficam à disposição para seguir a diante na esteira de qualidade.
4.5. Sobrevivência
Os registros de dados devidamente criticados e validados, após terem sido padronizados e possivelmente enriquecidos, são comparados contra a base de dados alvo e devidamente agrupados com a visão corporativa.
No entanto, a gravação na base única é feita usando o registro conhecido como Golden Record (Melhor registro). O Golden Record é composto de informações de quaisquer das instâncias desta entidade, podendo conter dados de diversos registros cuja informação tenha sido definida por meio de uma regra de sobrevivência estabelecida.
As regras de sobrevivência de registros visam estabelecer critérios para que o registro resultante do processo de unificação contemple as melhores informações possíveis (mais adequadas ao negócio), de forma automatizada;
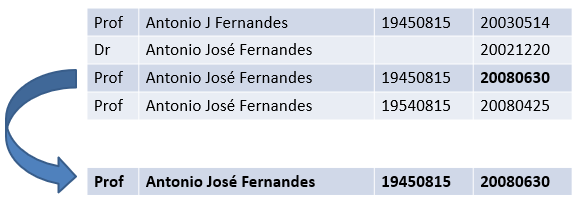
Como cada empresa possui sua particularidade, a solução permite a customização das regras para a definição/escolha da melhor informação. Essa escolha pode levar em consideração diversos critérios como:
- Menor / Maior (quantidade de caracteres);
- Mais frequente / Mais frequente não nulo;
- Igual a / Diferente de;
- Maior que / Menor que;
- Pelo menos um;
- Nomeação de atributo por meio de verificação dos sistemas de origem;
A partir da aplicação das regras é possível verificar os resultados e, caso necessário, alterá-las para sanar qualquer inconsistência verificada nos golden records.
Além dessas regras mais simples, é possível customizar regras mais complexas que levarão em consideração mais de uma informação ao mesmo tempo como por exemplo a regra abaixo:
Valor não nulo, conforme priorização abaixo. Para desempate levar em consideração o registro mais atual
1º - SISTEMA_RH
2º - SISTEMA_MARKETING
3º - SISTEMA_FINANCEIRO
Vamos entender a regra acima:
- Primeiro é priorizado a informação não nula, independente da origem;
- Com o grupo de registros que possuem a informação preenchida é priorizado por exemplo a origem da informação. O usuário de negócio com o conhecimento corporativo, definiu por exemplo que o nome da pessoa no SISTEMA_RH tem uma qualidade superior aos outros sistemas pois são validados por exemplo no E-Social.
- Por fim, caso esse sistema possua registros duplicados para desempate, o analista por exemplo definiu que o registro mais atual deve prevalecer.
Outro ponto importante e destacado na solução é que essas regras são customizadas por grupo de informação. Para a escolha do NOME é possível criar algo semelhante ao exemplo acima, porém para a escolha do melhor E-MAIL é possível definir uma regra diferente. Nesse caso pode ser que o sistema de marketing tenha uma informação mais atual e mais confiável. E é essa composição que formará o Golden Record.
5. Curadoria de Dados
5.1. Consulta Pessoas
A MD2 disponibiliza no Quality Manager uma interface de Consulta de Pessoas que possibilita executar a busca de titulares de forma simples e rápida.
Como resultado da pesquisa é possível verificar os dados unificadas para os diversos domínios tratados pelo MDM e também os registros que originaram a formação do Golden Record.
No link abaixo é possível acessar a Documentação do Quality Manager com os detalhes de como realizar a consulta de pessoas.
Consulta de Pessoas no Quality Manager
5.2. Tratamento de Dados Inválidos
A solução contempla uma camada de Quality Assurance (BQA) com o objetivo de assegurar o armazenamento de dados resultantes dos nossos processos de qualificação (padronização, crítica, enriquecimento). Existe um conjunto dentre as tabelas contempladas na camada BQA que armazena os dados invalidados por intermédio das críticas existentes no nosso motor.
Essas invalidações podem ocorrer por diversos motivos, como por exemplo falhas cadastrais ou até mesmo por cadastros mal intencionados. São essas regras de críticas, que garantem qualidade para que a informação possa ser persistida no MDM.
Exemplos de regras de crítica:
- Nome de Pessoa Física deve conter mais que uma palavra;
- Nome de Pessoa Física não pode conter palavrões;
- CPF, CNPJ, CNH devem possuir o dígito verificador válido;
- O E-mail deve possuir sintaxe válida;
- O Telefone não pode conter mais que onze dígitos.
Visando auxiliar nossos clientes na realização do tratamento de alertas e notificações referentes as críticas e validações provenientes do motor de crítica e unificação do MDM, atividade tão importante para o ciclo de gestão dos dados mestre, possibilitamos que a curadoria dos registros inválidos seja realizada no MD2 Quality Manager, na interface de Tratamento de Inválidos, acessível em:
Governança MDM > Tratamento de inválidos.
Nessa tela o usuário poderá trabalhar com uma série de filtros para focar exatamente onde deseja. Ele poderá delimitar o período de invalidação, o assunto (Conta, Contato, Contato Eletrônico, Documento, Endereço, Pessoa Física, Pessoa Jurídica, Pessoa Não Identificada e telefone), o motivo específico, o sistema. Ele pode inclusive filtrar pelo CPF se o desejar.
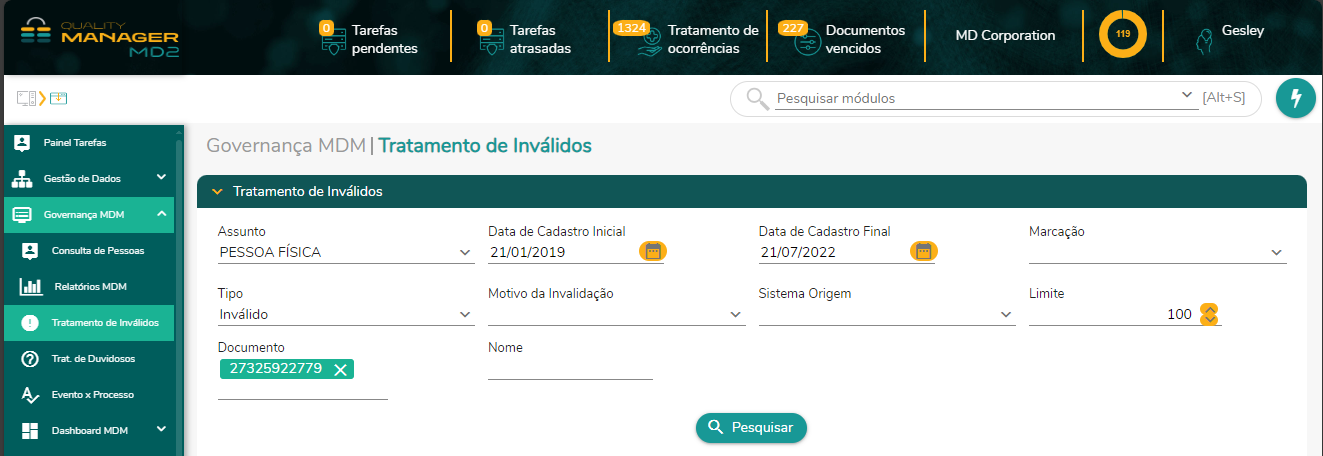
Após clicar em Pesquisar, são retornados os registros inválidos que atendem ao requisitos aplicados no filtro
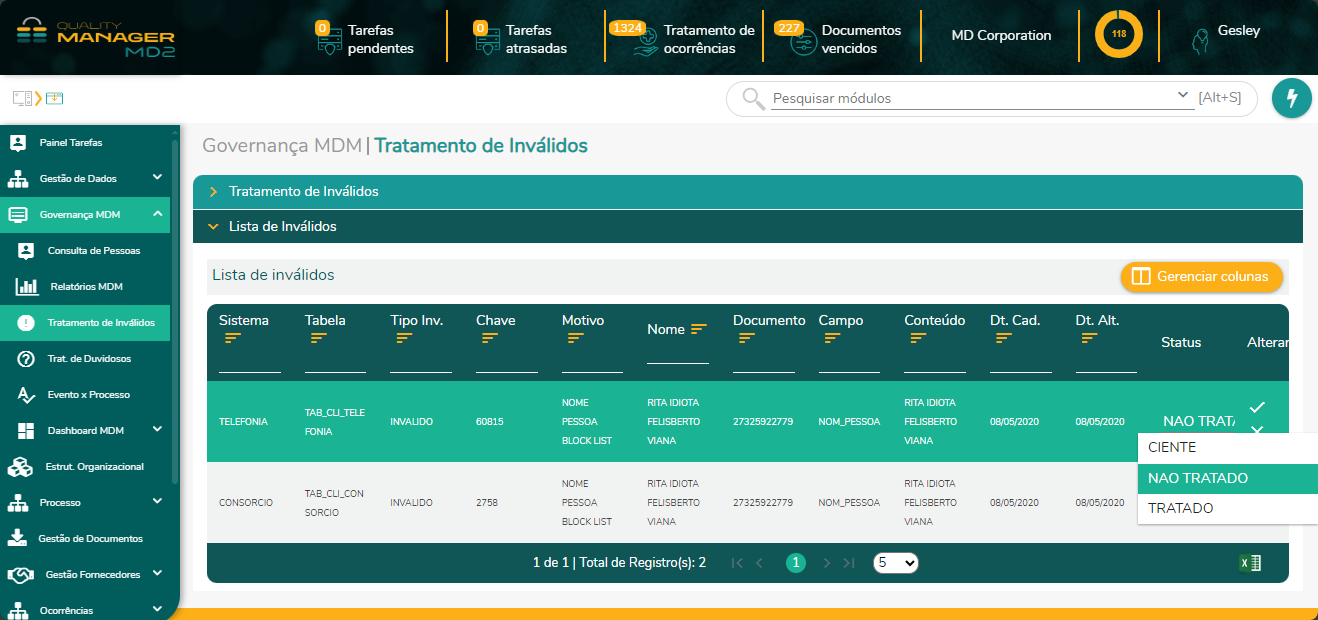
Ao fim, o usuário pode, de forma amigável, indicar o status de cada caso. Como acelerador para essa fase de curadoria, a MD2 propõe o desenho de um processo, chamado MDM002 - Processo de Curadoria, visando nortear o cliente na execução dessa atividade. É possível inclusive exportar um relatório com as informações resultantes dos filtros na interface.
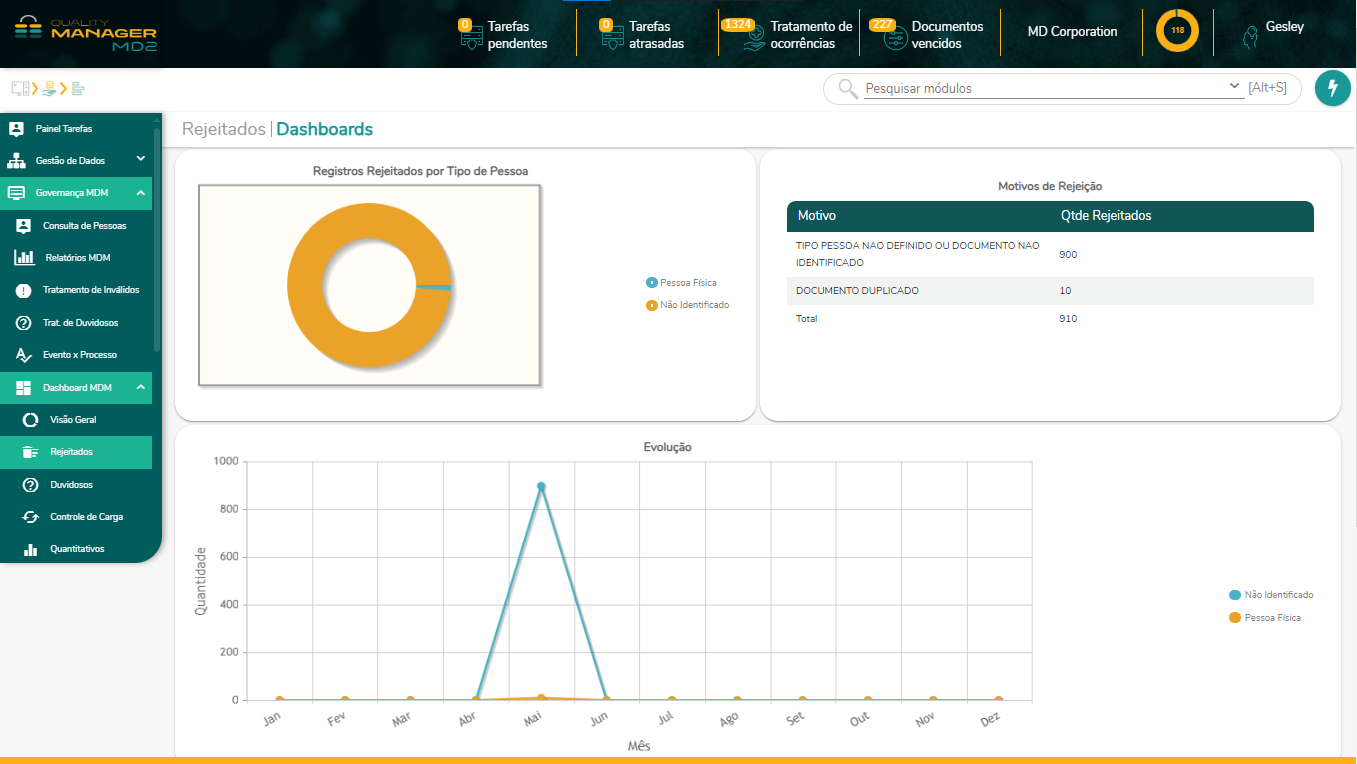
Outra funcionalidade disponível para a equipe de governança são os dashboards que trazem uma visão quantitativa e que pode ser acessado em:
Governança MDM > Dashboard MDM > Rejeitados
5.3. Tratamento de Duvidosos
O processo de identificação (matching) utiliza notas geradas por meio do algoritmo de verificação de duplicatas para indicar casos onde é necessário a criação de um novo golden record ou a associação do registro processado a um golden record existente.
Em casos onde a nota resultante do processo de matching não indica nenhum dos dois casos apontados anteriormente, chamamos o registro de Clerical ou Duvidoso.
Os registros duvidosos exigem análise manual para identificação da existência ou não de duplicidades. A curadoria desses casos é realizada via MD2 Quality Manager, na interface de Tratamento de Duvidosos, acessível em:
Governança MDM > Tratamento de Duvidosos
Nessa tela o usuário poderá trabalhar com uma série de filtros para focar exatamente onde deseja. Ele poderá escolher um determinado sistema, se é pessoa física ou jurídica e caso ele saiba o nome ou até mesmo o CPF/CNPJ ele poderá ir direto ao registro desejado.
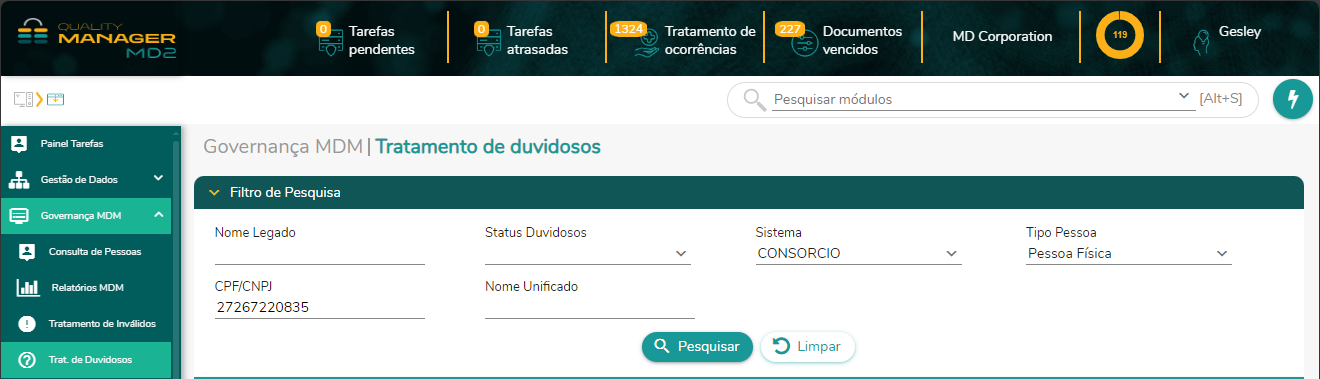
Após clicar em Pesquisar, são retornados os registros inválidos que atendem ao requisitos aplicados no filtro
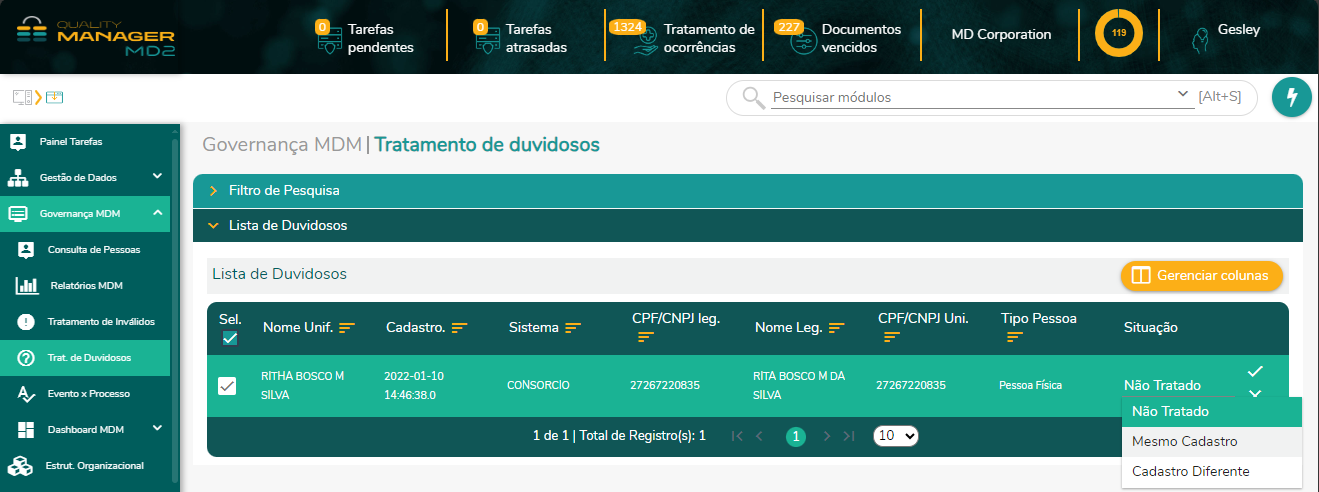
Ao fim, o usuário terá a lista de registros "pessoas" que estão como duvidosos e que atenderam aos filtros aplicados. Essa lista poderá ser exportada em formato Excel para um estudo mais aprofundado, assim como para enviar aos devidos responsáveis caso seja identificado alguma inconsistência. Após realizada a análise, o analista deverá atualizar a situação informando se o mesmo se trata de fato do Mesmo Cadastro, ou se é um Cadastro Diferente. Uma vez confirmada a sua operação essa informação é salva e na próxima execução do motor de qualidade do MDM, ele levará em consideração a informação recebida e o registro inicialmente considerado como duvidoso passará a integrar um Golden Record seja o mesmo cadastro se assim o analista assinalou ou como um cadastro diferente.
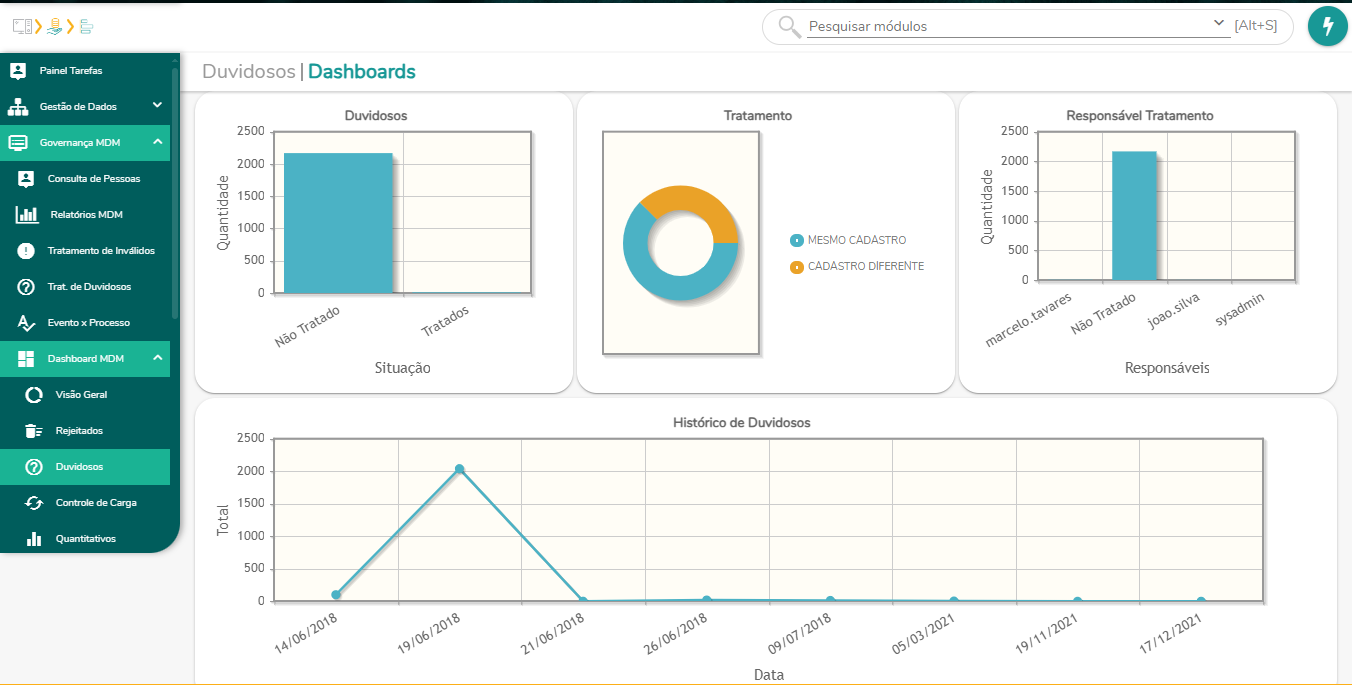
Outra funcionalidade disponível para a equipe de governança são os dashboards que trazem uma visão quantitativa e que pode ser acessado em:
Governança MDM > Dashboard MDM > Duvidosos
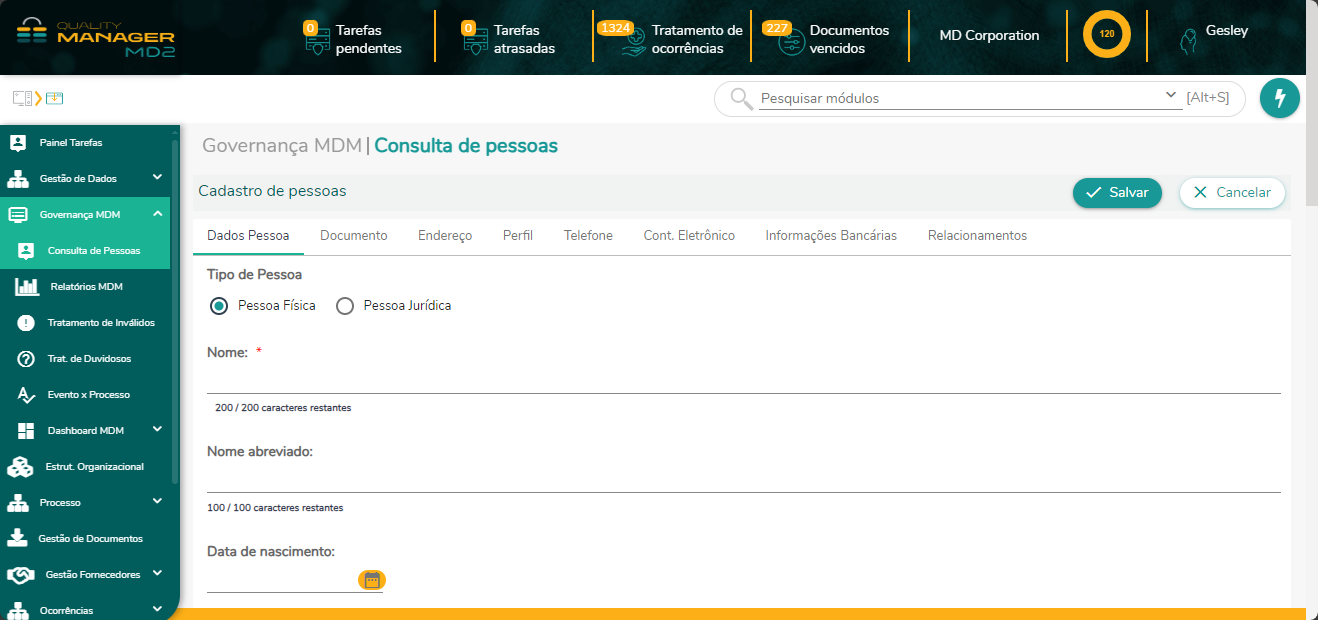
5.4. Cadastro e Edição de Golden Records
O CRUD MDM permite que os usuários com as devidas permissões possam cadastrar, visualizar, editar/atualizar e excluir dados de pessoas unificadas (Golden Record) através da interface da Consulta de Pessoas do MD2 Quality Manager, para posterior processamento no fluxo do MDM
Os seguintes domínios podem ser manipulados dentro desta funcionalidade: Pessoa Física, Pessoa Jurídica, Documento. Endereço, Telefone, Contato Eletrônico, Perfil, Conta Bancária, Relacionamento e Sócio.

6. Publicação de Dados
6.1. Publicação por Serviços Web (SOA)
Um Web service é um conjunto de métodos que podem ser invocados por outros programas utilizando tecnologias Web. É utilizado para transferir dados através de protocolos de comunicação padronizados acessíveis diferentes plataformas de forma desacoplada, ou seja, independentemente das linguagens de programação ou tecnologias específicas utilizadas nessas plataformas, integrando mais informação e novas funcionalidades de forma simples e rápida.
O diagrama abaixo ilustra como essa característica da solução pode ser utilizada em um cenário corporativo, através da exposição dos serviços e opcionalmente controlando o acesso via ESB (Enterprise Service Bus).
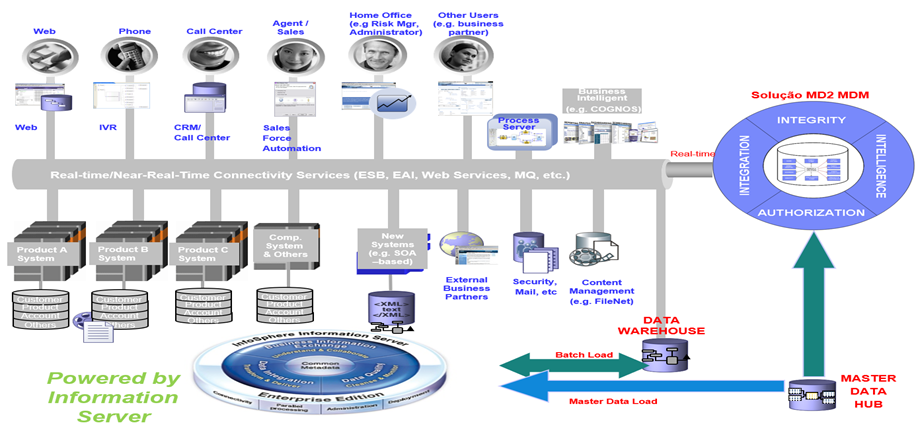
A arquitetura orientada a serviços (SOA) do InfoSphere Information Server garante que a lógica de integração de dados desenvolvida possa ser usada por qualquer processo de negócios. Os melhores dados estão disponíveis o tempo todo, para todas as pessoas e para todos os processos.
A solução MD2 contempla um conjunto de serviços capaz de facilitar o acesso aos dados mestre. Desta forma, as operações de consulta e manipulação de cadastros pode ser feita diretamente, através de um conjunto de serviços disponíveis para este fim.
6.2. Publicação por Filas de Mensageria
A comunicação por troca de mensagens é outra forma de publicação de dados disponível na solução de MDM da MD2. A estratégia de publicar e assinar mensagens é particularmente útil para processos de retroalimentação de dados, ou seja, o envio do Golden Record a partir do HUB MDM para leitura pelos sistemas legado de forma proativa,
O diagrama abaixo ilustra esta estratégia de publicação de dados da solução.
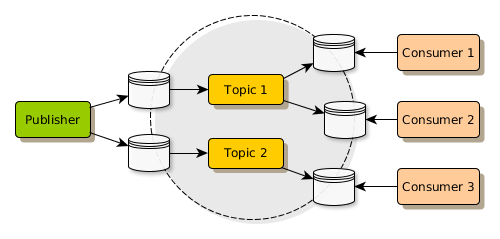
É uma forma de comunicação assíncrona de serviço a serviço usada em arquiteturas de micro serviços. Em um modelo pub/sub, qualquer mensagem publicada para um tópico é imediatamente recebida por todos os assinantes do tópico. As mensagens podem ser usadas para permitir arquiteturas orientadas a eventos, ou para desacoplar aplicações a fim de aumentar o desempenho, confiabilidade e escalabilidade.
Observando o caso de uso específico da solução MDM na perspectiva da estratégia de retroalimentação, essa arquitetura de publicação se mostra extremamente útil e versátil. Toda vez que alguma modificação de dados ocorre no Golden Record, este cadastro masterizado é publicado em uma fila de mensagem, normalmente utilizando uma estrutura genérica representada por um modelo canônico de dados. Dessa forma, todos os assinantes dessa fila, ou seja, outros sistemas legado que também possuem interligação lógica com este Golden Record, recebem esta atualização de forma assíncrona e após realizarem as respectivas adequações estruturais e as traduções de domínios de dados, podem atualizar sua base de dados com a versão mais rica possível dos dados deste indivíduo que foram centralizadas no HUB MDM.
6.3. Publicação de Arquivos
Em contextos onde os dados a serem publicados são de natureza tabular (dados organizados em tabela), é comum que estejam armazenados numa base de dados e sejam facilmente transportados para algum arquivo adequado ao armazenamento de dados tabulares, como arquivos CSV ou TXT.
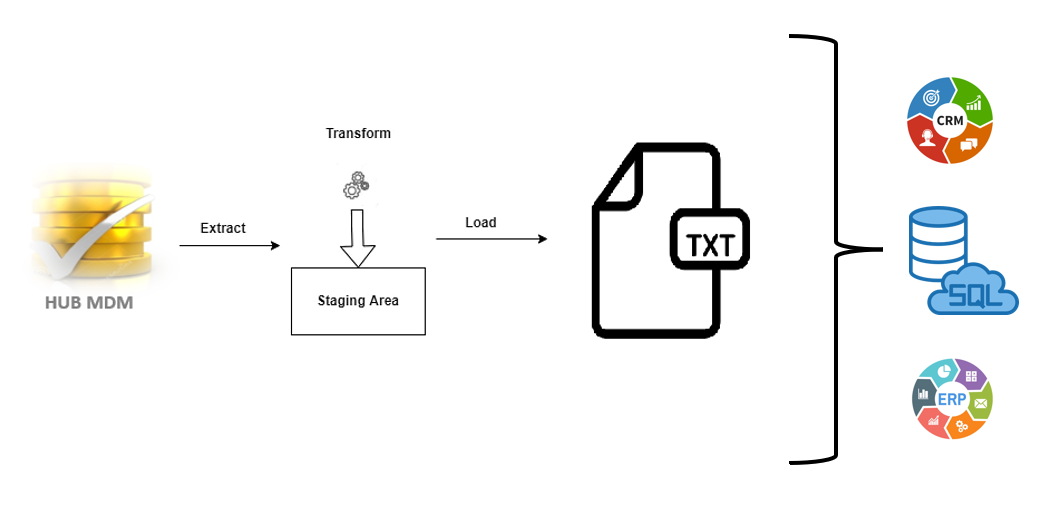
Esta estratégia de publicação de dados se faz extremamente útil quando as aplicações de destino já possuem algum tipo de funcionalidade para a importação de dados a partir de arquivos. Desta forma, a geração dos dados neste arquivo pode utilizar as robustas rotinas ETL para gerar arquivos de dados na estrutura correta adequada à aquela aplicação em particular.
6.4. Publicação por Integração de Dados (ETL)
ETL é um acrônimo para as palavras em inglês Extract, Transform e Load. Refere-se aos procedimentos de extração, transformação e carregamento de dados para um ambiente integrado. Os processos ETL são altamente eficientes no quesito integração de dados, estabelecendo regras de otimização e manipulação padronizada dos dados a fim de facilitar sua inserção em ferramentas ou ambientes integrados.
O diagrama abaixo ilustra estratégia de publicação de dados por ETL.
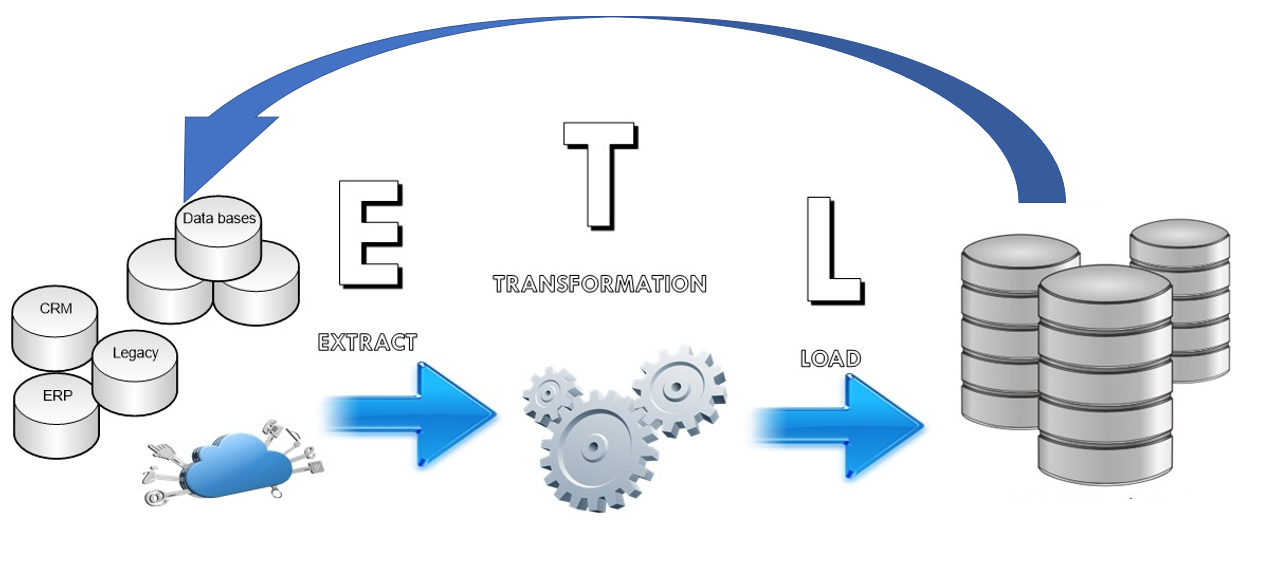
A publicação de dados mestre através de ETL permite alta flexibilidade na formatação de dados e na aplicação de regras mais robustas de integração ou qualidade de dados, porém cria maior acoplamento entre aplicações uma vez que grava os dados mestre diretamente nas bases de dados das aplicações interessadas, criando uma forma de publicação mais invasiva na ótica dos administradores responsáveis por estes outros sistemas.
7. Histórico e Rastreabilidade no MDM
7.1. Camada Histórico Staging Area
A solução contempla uma camada no modelo que funciona de forma similar a uma réplica da camada STG, com o objetivo de manter N cópias dos dados alterados.
A principal diferença entre a camada STG e a camada H_STG é que a primeira possui sempre a versão mais atual do registro e é essa versão do dado que passa pelo motor de qualidade. Já a camada H_STG possui o histórico do registro ao longo do tempo. O período de manutenção desse histórico é parametrizado e pode ser alterado de acordo com a necessidade de cada negócio.
A manutenção desse histórico no modelo muitas vezes é o único histórico desse dado na companhia como um todo. A grande maioria dos sistemas não possui esse histórico a não ser que seja restaurado o backup de uma foto do passado, o que dificulta o entendimento do comportamento do dado. Por ter esse dado ao alcance do analista fica fácil compreender a evolução do dado e assim consegue-se responder perguntas e até mesmo auditorias baseadas em fatos e não em intuição.
Caso seja identificado durante uma auditoria que o dado foi manipulado erroneamente o analista poderá acessar seu histórico e com base nos dados ali armazenados o mesmo poderá fazer a correção no sistema de origem para a visão desejada.
7.2. Status de Qualificação
Para ajudar a compreender o dado final que é apresentado na interface de curadoria a solução armazena o status (original, enriquecido, padronizado, validado) das informações de forma individual. Dessa forma é possível rastrear as operações de tratamento as quais um dado foi submetido entre as camadas integrada e unificada.
A ênfase dada para o status individual, se da pois cada parte do dado tem uma informação diferente. Pegando como exemplo um endereço, o campo Tipo Logradouro ele pode ter sido padronizado para RUA, já o campo Bairro pode ter sido enriquecido, ou seja inicialmente o cadastro não possuía tal informação, porém após passar pelo motor de qualidade e pelas regras de enriquecimento, o bairro foi aferido com base no CEP por exemplo.
Para visualizar o status de qualificação basta entrar no cadastro desejado e em cada uma das abas segmentadas por assunto pode-se passar o mouse em cima das informações. Uma caixa suspensa aparecerá imediatamente com a informação.
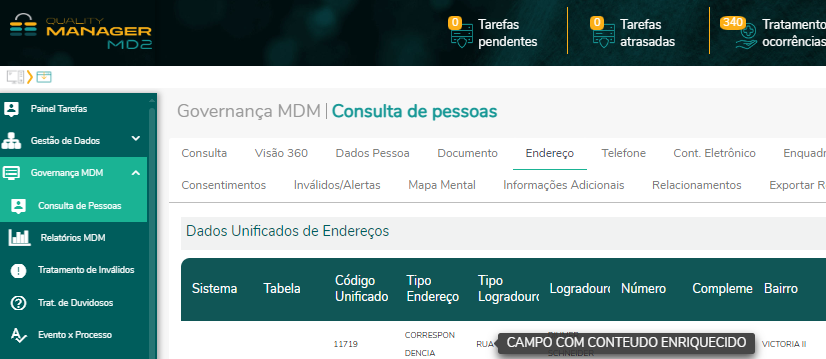
Imagem ilustrativa demonstrando que a informação foi enriquecida pelo motor de qualidade do MD2 MDM
7.3. Trilha de Unificação
Após a unificação dos registros e a composição do Golden Record, é extremamente importante conhecer a origem da informação.
- Qual sistema?
- Qual tabela?
- Qual o código interno do referido sistema?
- Quando o registro foi criado?
Essas são algumas das perguntas mais comuns e que são facilmente respondidas pela solução, uma vez que existe toda uma camada de rastreabilidade.
Uma vez visualizando as informações de um registro no portal de curadoria, O Analista observará que a tela de cada assunto é dividida em duas. Na primeira metade da tela terá a visão corporativa do titular, ou seja, o Golden Record. Já na parte inferior estarão todas as origens daquele titular.
Além de visualizar facilmente as origens da pessoa, é possível compreender a composição do Golden Record. Observe que existem registros da origem com informações faltantes, mas a união de todas as origens conseguiu agregar valor para a companhia gerando a melhor versão possível para o titular.
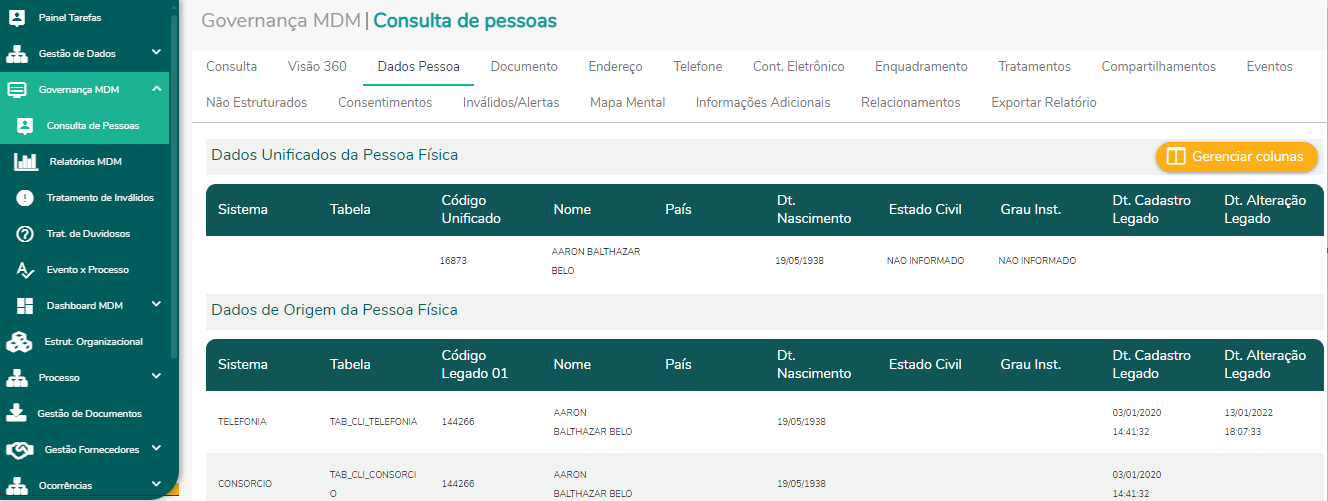
Imagem ilustrativa da rastreabilidade do titular.
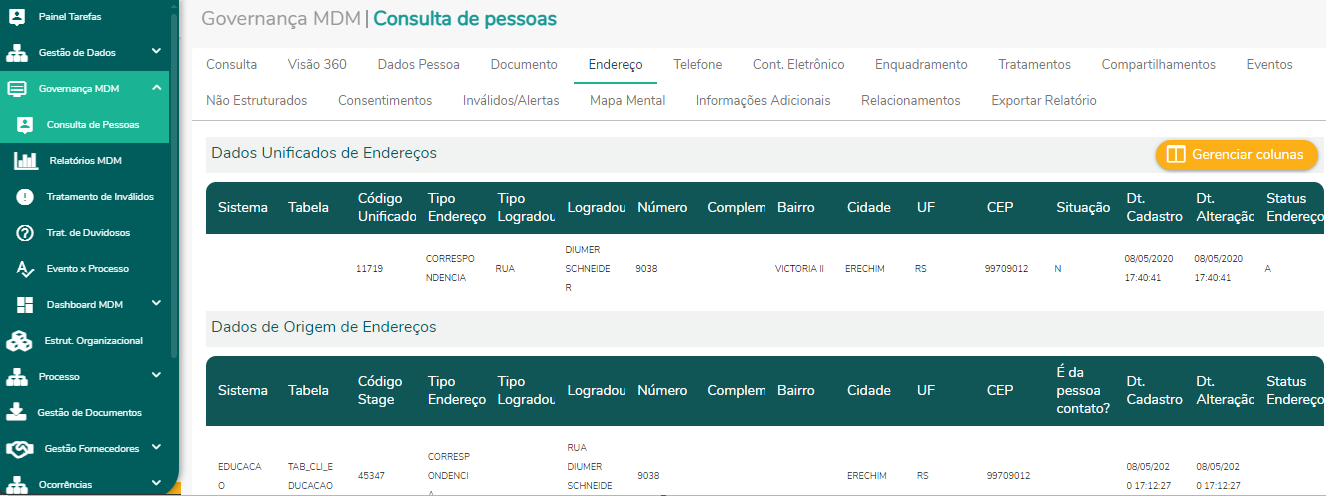
Imagem ilustrativa da rastreabilidade dos endereços do titular.
Nossa modelagem armazena o histórico de unificações, portanto registros de origem que ocasionalmente mudam suas referências na camada BUP (Golden Record), por diversos motivos, como por exemplo processo de Split-Merge, são passíveis de rastreabilidade.
8. Representação de Relacionamentos no MDM
Relacionamento remete a ligação (profissional, familiar, localidade, ...). Identificar os inúmeros relacionamentos entre as pessoas é de extrema importância para qualquer corporação. Primeiro porque agrega informação ao dado, segundo porque pode trazer insight às equipes. A equipe de marketing por exemplo pode enxergar uma oportunidade, baseada em um relacionamento familiar, lançar um produto específico para o dia dos pais, ou ainda um produto voltado para uma família numerosa. No MDM esses relacionamentos podem ser vistos em diversas situações. O primeiro focado no endereço da pessoa com o objetivo de identificar por exemplo grupos familiares e denominado de House Holding conforme descrito no tópico 8.1. Já o segundo é aberto e permite a criação de qualquer que seja o relacionamento utilizado na empresa (Pai, Filho, Irmão, chefe, sócio, ...) sem limites de ligações e/ou hierarquia, conforme pode ser visto no tópico 8.2
8.1. House Holding
House Holding pode ser entendida como a base unificada de endereços. Seu objetivo é identificar e agrupar as pessoas que compartilham de um mesmo endereço e que podem ser interpretadas como um mesmo grupo familiar, colegas de trabalho, dentre outros.
Essa informação traz inteligência ao negócio possibilitando assim uma visão estratégica para auxílio as diversas ações de relacionamento com o cliente, tornando as mesmas mais assertivas e qualificadas, como por exemplo:
- Direcionar uma campanha específica para um grupo familiar sendo mais direta em atingir seu público-alvo. Qual a probabilidade de vender uma van para uma pessoa solteira versus a probabilidade de vender para uma família numerosa?
- Reduzir o custo de marketing e atender às preferências da família versus as preferências individuais dos clientes;
8.2. Estrutura de Relacionamento
É de extrema importância para a estratégia de negócios a visão de relacionamentos/associações entre as pessoas existentes no universo de dados da organização, podemos citar:
- Relacionamento familiar (Pai, filho, irmã, avó, ...)
- Relacionamento profissional (Chefe, Sócio, Pares, ...)
- Relacionamento financeiro (Avalista, Fiador, Mutuário, ...)
- Relacionamento estudantil (Estudante, Professor, Diretor, ...)
- ...
Os relacionamentos não são pré-definidos no modelo, dessa forma, fica a critério da empresa definir e mapear as relações existentes entre as "pessoas", inclusive permitindo ligações n:n, podendo uma pessoa ao mesmo tempo ser:
- subordinado do XXX
- chefe do AAA, BBB, CCC
- pai do WWW e do QQQ
- filho do LLL
- ....
Nesse contexto, o MD2 MDM propõe uma estrutura de relacionamentos partindo da extração e passando por todas as camadas e processamentos existentes no motor. A interface de Consulta de Pessoas do MD2 Quality Manager permite a visualização dos relacionamentos existentes para uma determinada pessoa.
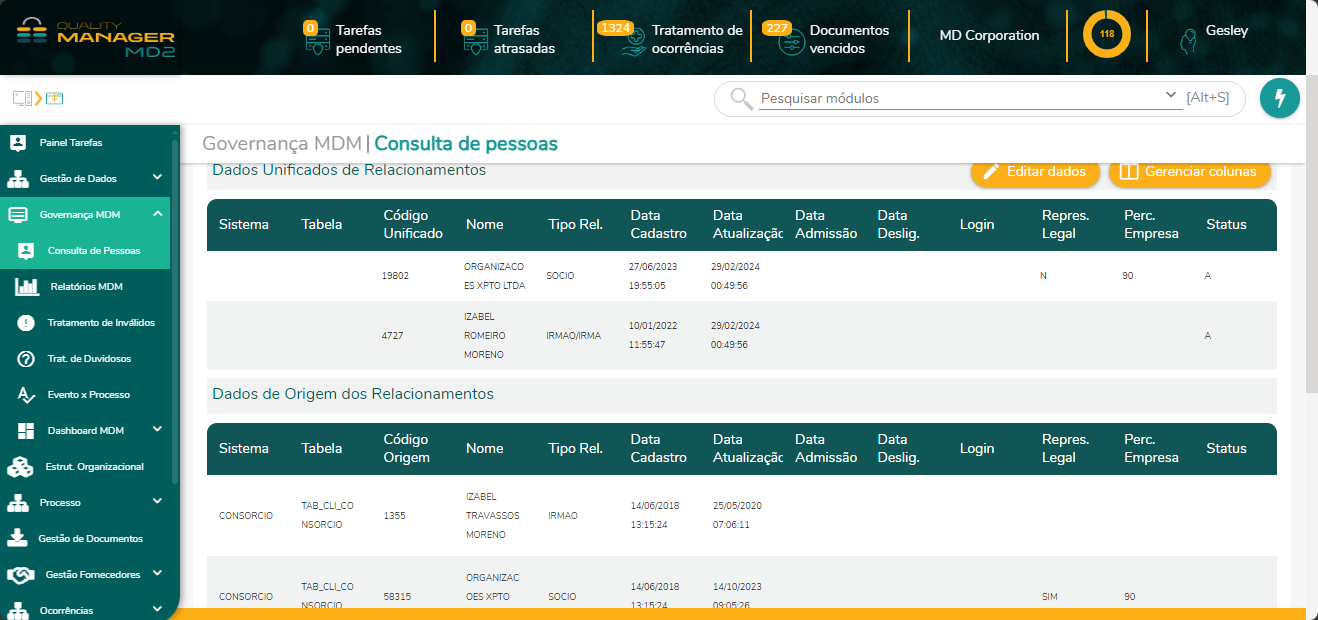
8.3. Apresentação de Relacionamentos
É possível verificar os relacionamentos armazenados na solução MD2 MDM por meio da interface do MD2 Quality Manager, que permite uma visão de grafos acerca dos relacionamentos, conforme é possível verificar na imagem abaixo.
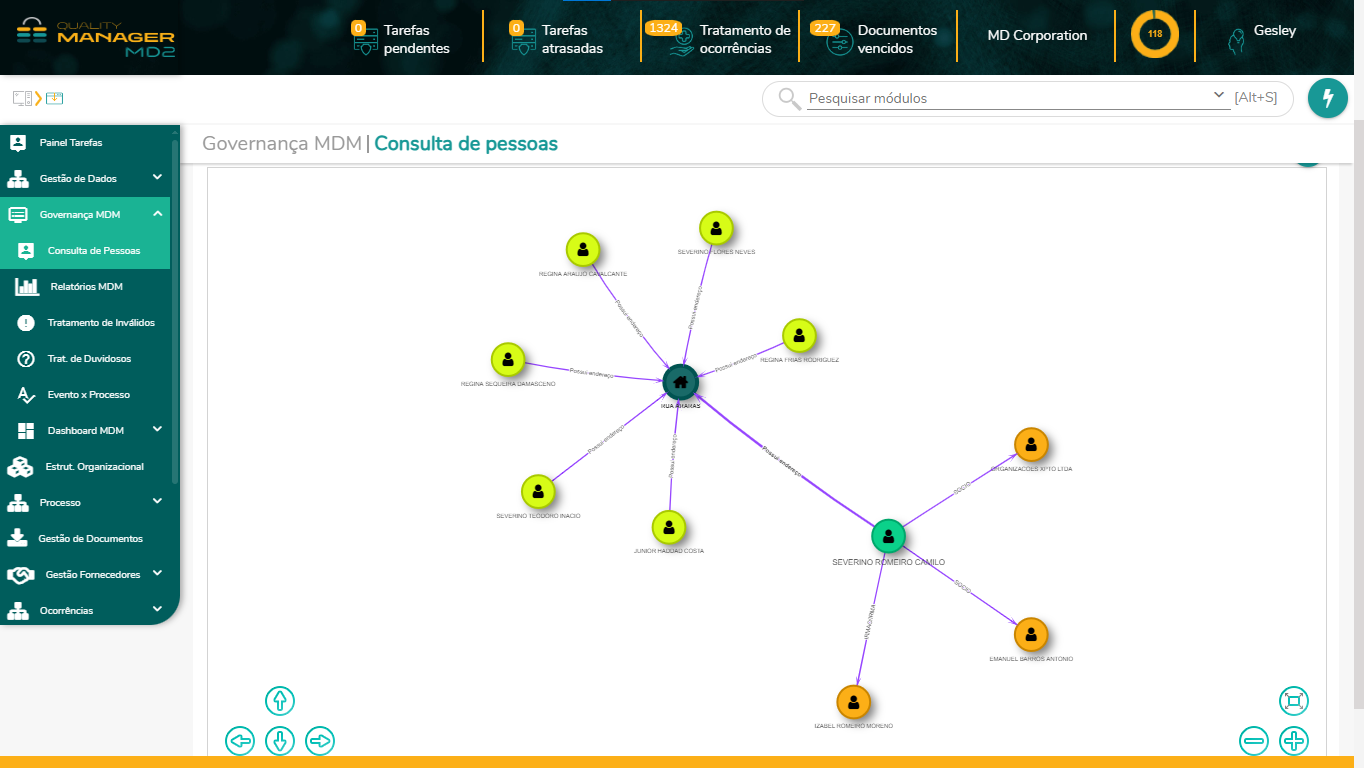
Optou-se por essa visão por garantir também a apresentação de possíveis hierarquias que possam se formar a partir dos relacionamentos cadastrados.
8.4. Exemplos de Hierarquia
A liberdade proposta pela camada de relacionamentos da solução MD2 MDM para criação e armazenamento de dados permite que hierarquias sejam suportadas. Seguem abaixo exemplos práticos para ilustrar a possibilidade levantada:
Hierarquia Equilibrada
Representação onde os ramos da hierarquia descem ao mesmo nível, que por sua vez representa o mesmo tipo de informação e é logicamente equivalente.
É possível citar um relacionamento onde o primeiro nível da hierarquia é um grupo da área hospitalar, o segundo nível é referente aos hospitais e formado por um relacionamento Pertence, e o terceiro nível contempla o executivo-chefe de cada hospital, sendo formado por um relacionamento Chefia.
Hierarquia Desequilibrada
Incluem níveis logicamente equivalentes, mas cada ramo da hierarquia pode descer a um nível diferente. Em outras palavras, uma hierarquia desequilibrada contém membros da folha em mais de um nível.
Para exemplificar esse caso é possível citar relacionamento Filho(a), que formam uma árvore genealógica, onde o algum dos membros não tenha um filho.
Hierarquia Recursiva
Representações onde uma entidade tem um atributo baseado em domínio baseado na própria entidade. Um exemplo é uma estrutura organizacional, onde cria-se um relacionamento Chefia, em que um funcionário A pode gerenciar outro B, e esse mesmo funcionário B pode gerenciar uma pessoa C.
9. Split Merge
O motor de qualidade do MDM provê processos com a responsabilidade de verificar se as alterações ocorridas nos sistemas de origem irão provocar a separação ou junção de um registro ao Golden Record. Como os cadastros são vivos podem ocorrer alterações que ocasionem alguma dessas ações de Split ou Merge e a solução está preparada para ambas as situações.
9.1. Split
Supondo que em um dos sistemas de origem da empresa tinham dois registros 99% idênticos. Esse 1% diferente se dá unicamente por conta de uma única letra nos nomes (MARCUS e MARCOS).
 Imagem ilustrativa para ilustrar o caso de uso
Imagem ilustrativa para ilustrar o caso de uso
Esses registros correspondem à mesma pessoa?
Para responder a essa pergunta deve-se ater a um pequeno grupo de informação.
- Tem o mesmo nome? Apenas 1 letra de diferença.
- Tem o mesmo CPF? SIM
- O nome da mãe é idêntico? SIM
- A data de nascimento é a mesma? SIM
Considerando essas informações o motor de qualidade do MDM considerou os dois registros como sendo uma mesma pessoa, porém o analista ao validar seu cadastro observou que ambos os cadastros estavam utilizando um CPF genérico. Após essa identificação, o analista ajustou o cadastro para os CPF corretos.
 Imagem ilustrativa do ajuste no cadastro. Os CPFs agora são diferentes
Imagem ilustrativa do ajuste no cadastro. Os CPFs agora são diferentes
O motor de qualidade do MDM ao identificar qualquer atualização dos dados valida novamente o registro e nessa situação realizará a operação de SPLIT, pois de acordo com os novos dados, mesmo tendo um nome muito parecido, o mesmo nome da mãe e até mesma data de nascimento é possível afirmar que se tratam de duas pessoas distintas.
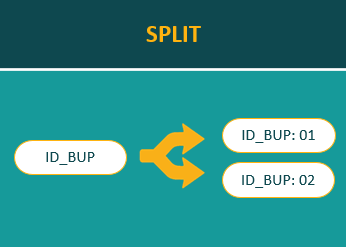
Imagem ilustrativa do SPLIT
9.2. Merge
Para esse cenário, deve-se levar em consideração que existem dois registros que foram inicialmente considerados distintos pois seus dados em um determinado momento estavam divergentes, fazendo com que as regras de matching do motor de qualidade de dados do MDM o considerassem diferentes.
Imagem ilustrativa dos dois registros com divergências cadastrais fazendo com que os mesmo fossem considerados divergentes num primeiro momento
Após um analista observar um erro no cadastro foi realizado o ajuste no mesmo, fazendo com que ambos os registros agora possuíssem o mesmo CPF.
Imagem ilustrativa após os ajustes no cadastro
Nesse momento, o motor de qualidade do MDM ao identificar qualquer atualização dos dados, valida novamente os registros e nessa situação realizará a operação de MERGE pois de acordo com os novos dados, os dois registros serão considerados a mesma pessoa, mesmo ainda tendo o nome com uma divergência, "com erro cadastral".
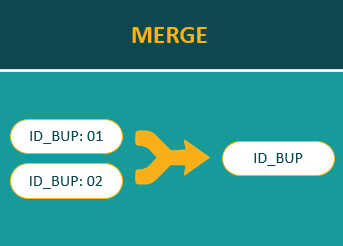
Imagem ilustrativa da operação de MERGE
10. Governança do MDM
Quando fala-se de governança é sobre aplicar o uso de melhores práticas com o objetivo de gerar um ambiente eficiente no apoio a decisão, controlando os metadados de negócio e técnicos, assegurando-se da aplicação das políticas e regras corporativas sobre os dados.
10.1. Ativos de Dados - Termos
Um termo é uma palavra ou frase que descreve uma característica da empresa. Os termos são o bloco de construção fundamental do glossário. Ao criar um termo, você o define especificando suas propriedades. As propriedades de um termo lhe dão significado e o diferenciam de outros termos.
Todos os termos associados ao MDM estão documentados no InfoSphere Information Governance Catalog (IGC). Vão desde termos mais técnicos e bem específicos como STG, BIP, BUP, BCR, BQA a termos de negócio como Integração de Dados, Dados Pessoais e Dado Sensível.

Imagem ilustrativa do termo BUP

Imagem ilustrativa do Termo Dado Sensível
10.2. Ativos de Dados - Políticas
As políticas de governança são usadas para descrever e documentar as diretrizes, regulamentos, padrões ou procedimentos de sua organização para garantir que os ativos de dados e informações sejam gerenciados e usados de maneira adequada.
Assim como os termos, as políticas associadas ao MDM estão documentados no InfoSphere Information Governance Catalog (IGC) e estão agrupados dentro da hierarquia 01 - Políticas de Governança de Dados > 02 - Políticas de Gestão de Dados Mestre.

10.3. Ativos de Dados - Regras
Conjunto de passos e ações que permitem a modificação dos dados a partir das regras definidas junto a área de governança de dados. De acordo com suas regras de negócio, você pode determinar como seus dados são organizados, categorizados, enriquecidos e gerenciados.
Assim como os termos e as políticas as regras de dados (Padrinização, Enriquecimento, Crítica, Sobrevivência) associadas ao MDM estão documentados no InfoSphere Information Governance Catalog (IGC).
Imagem ilustrativa da lista de regras

Imagem ilustrativa da regra: Crítica Nome Nulo
11. Análise da Qualidade dos Dados
Nossa solução se utiliza do InfoSphere® Information Analyzer com o intuito de fornecer recursos para traçar o perfil e analisar dados para fornecer informações confiáveis aos usuários.
Por intermédio de amostras e volumes completos de dados a qualidade e estrutura dos mesmos é avaliada. A análise das informações geradas permite que sua organização corrija problemas de estrutura ou validade antes que afetem seu projeto de integração de dados.
O Information Analyzer foi desenvolvido para auxiliar o analista de negócios e de dados a entender o conteúdo, a qualidade e a estrutura das fontes de dados através de um processo de análise automática dos dados.
A ferramenta possui interface amigável e diversas formas de análise onde o usuário só necessita apontar as fontes de dados os quais pretende analisar.
A arquitetura da suite IBM InfoSphere Information Server permite que os resultados das análises sejam compartilhados com as outras ferramentas da suite. A partir desse compartilhamento, é possível utilizar o IBM InfoSphere Information Governance Catalog para realizar consultas e relatórios Ad-Hoc de forma prática.
Seguem imagens ilustrando exemplos de utilização da ferramenta no contexto da solução MD2 MDM.
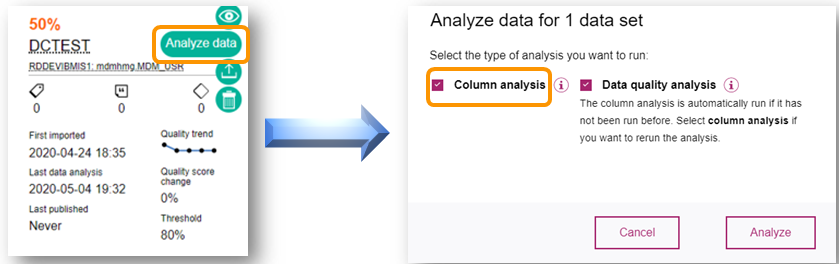
O passo inicial é executar Column Analysis nas fontes de dados que deseja analisar.
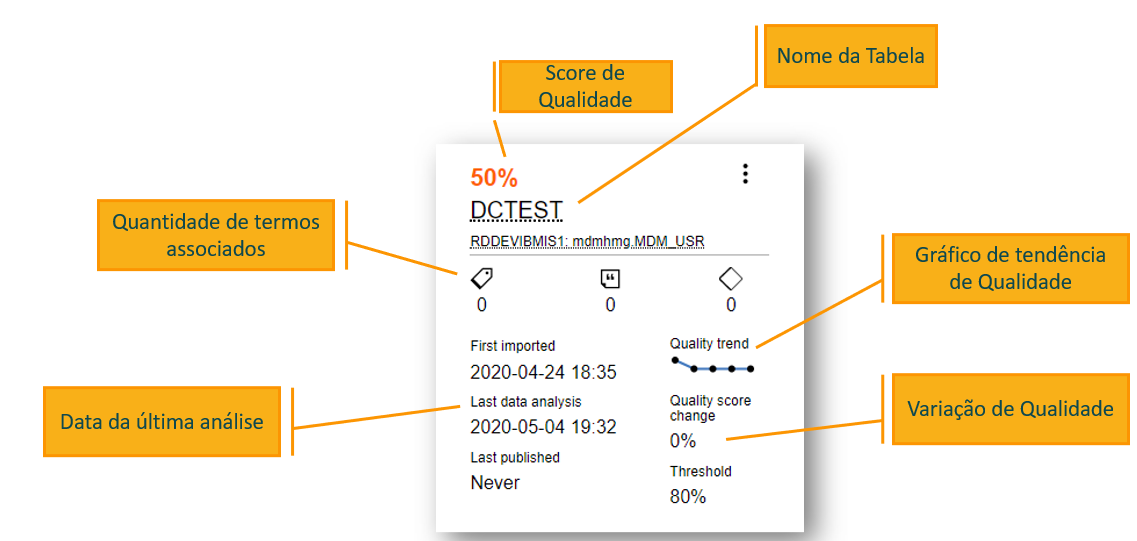
Os resultados do Column Analysis geram indicadores e informações relacionadas a qualidade dos dados analisados.
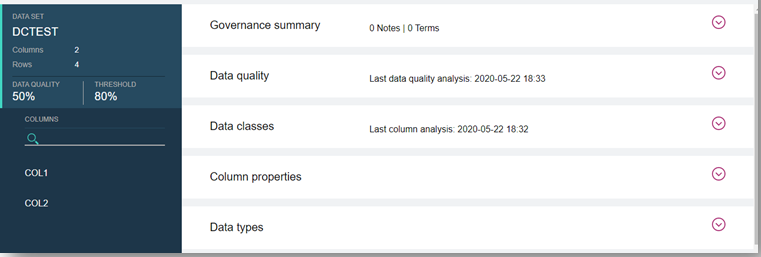
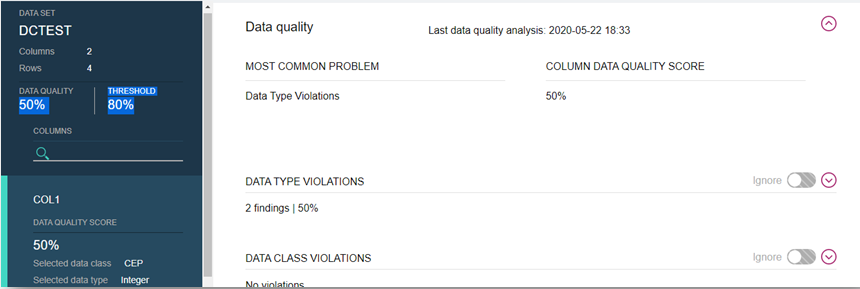
Os indicadores e informações podem ser consultados de forma rápida e interativa na interface web da ferramenta.
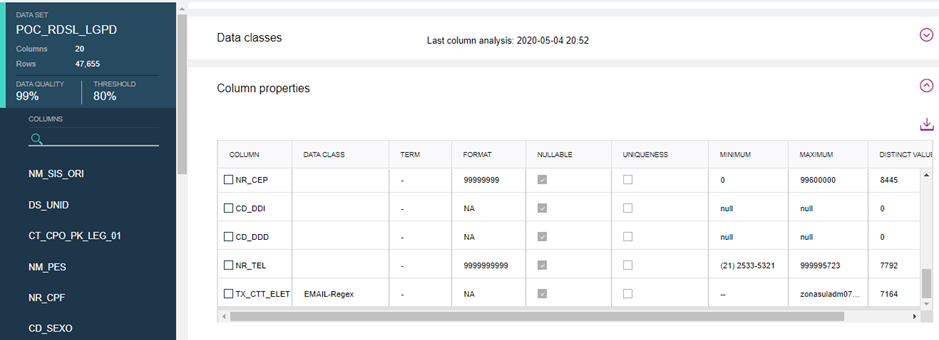
É possível que o usuário escolha a granulometria da avaliação (Tabela, coluna).
A partir da publicação dos resultados é possível utilizar o módulo de Consultas do Information Governance Catalog para gerar relatórios Ad Hoc acerca das análises de qualidade realizadas pelo IBM Information Analyzer.
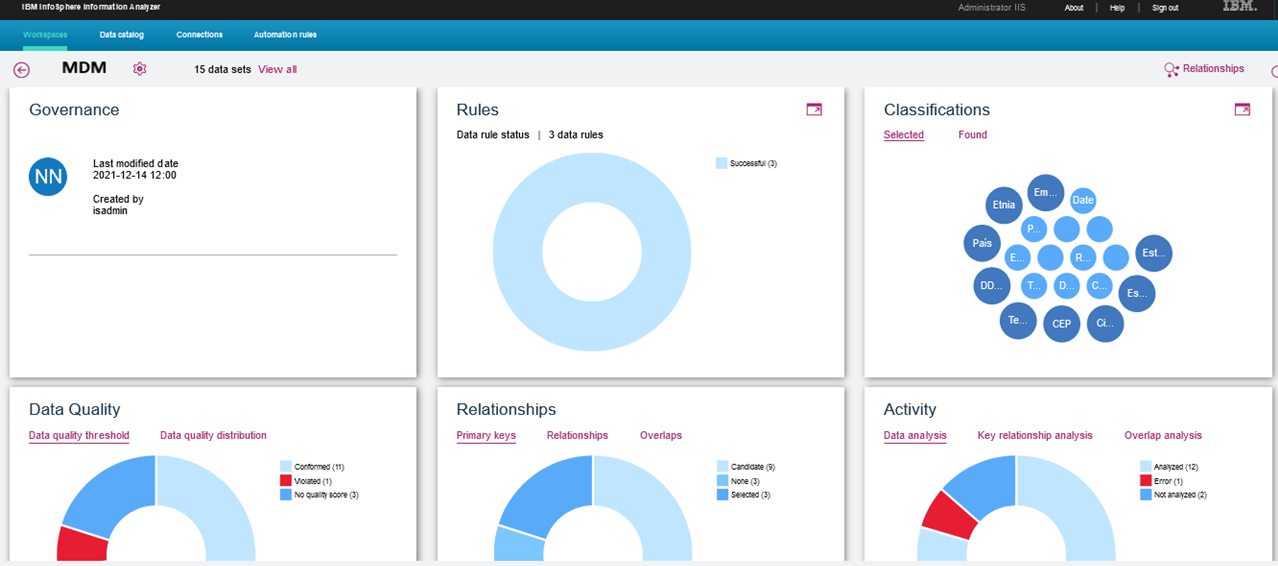
A ferramenta também possibilita a gestão das análises de profilling e qualidade de dados realizadas por intermédio de um dashboard presente na interface Web do Information Analyzer e também pela possibilidade de gerar reports pelo cliente da aplicação.
12. Relatórios MDM
Via MD2 Quality Manager a solução MD2 MDM possibilita a consulta e emissão de relatório relacionados ao MDM.
12.1. Controle de Cargas
Relatório que permite a consulta e emissão de informações referentes a última execução dos processos de cada camada, dessa forma possibilitando a gestão e verificação da reconciliação dos dados, onde os processos de ingestão de dados das origens, limpeza e consolidação ocorrem.
Permite-se filtros por status da carga e camadas.
12.2. Histórico de Cargas
Relatório que permite a consulta e emissão de informações referentes ao histórico de execuções dos processos de cada camada, dessa forma possibilitando a gestão e verificação da reconciliação dos dados, onde os processos de ingestão de dados das origens, limpeza e consolidação ocorrem.
Permite-se filtros por status da carga e camadas.
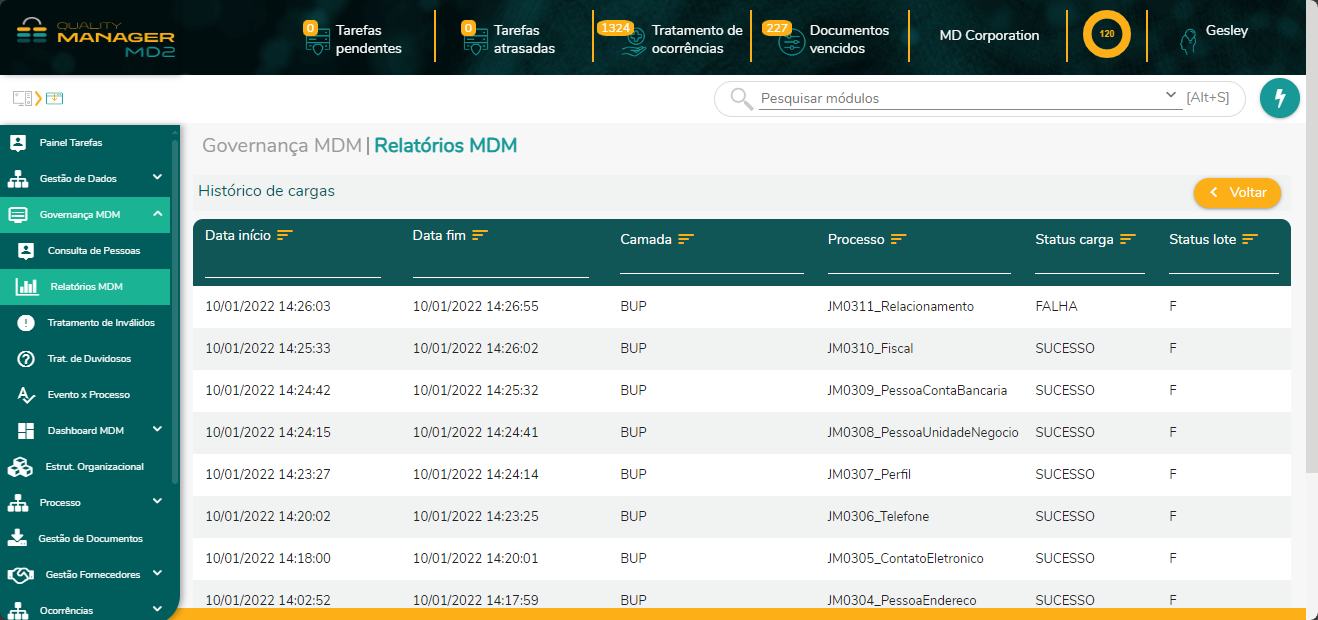
12.3. Qualificação
Relatório que permite a consulta e a emissão de informações relacionadas aos status (original, enriquecido, padronizado, validado) de qualificação dos atributos de dados mestres, auxiliando na compreensão do dado final apresentado na interface de consulta, inclusive se o dado é original. É possível rastrear as operações de tratamento as quais um dado foi submetido entre as camadas integrada e unificada.
É possível filtrar as informações por Assunto, Atributo e data de processamento.
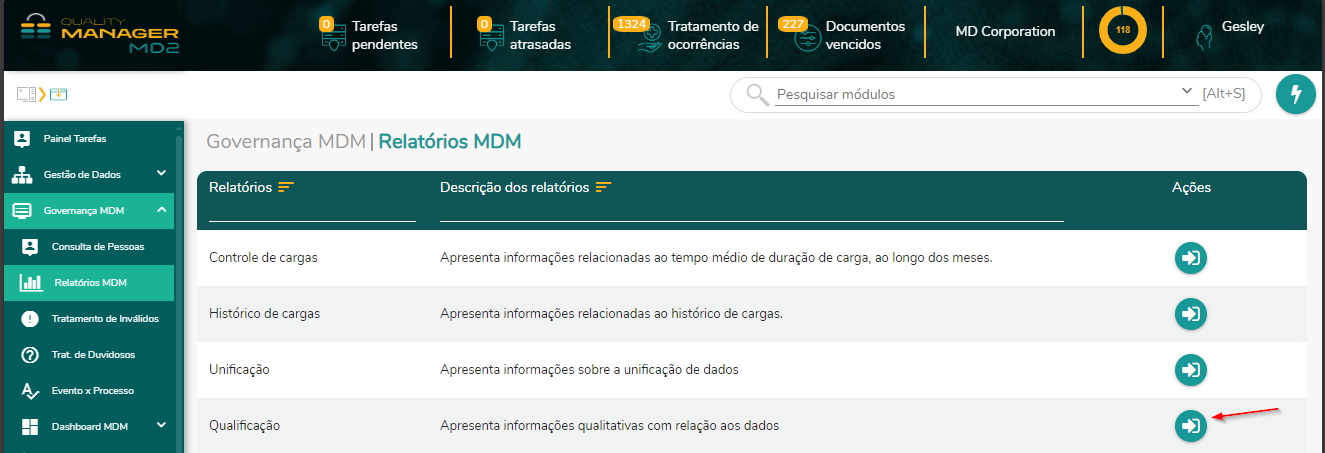
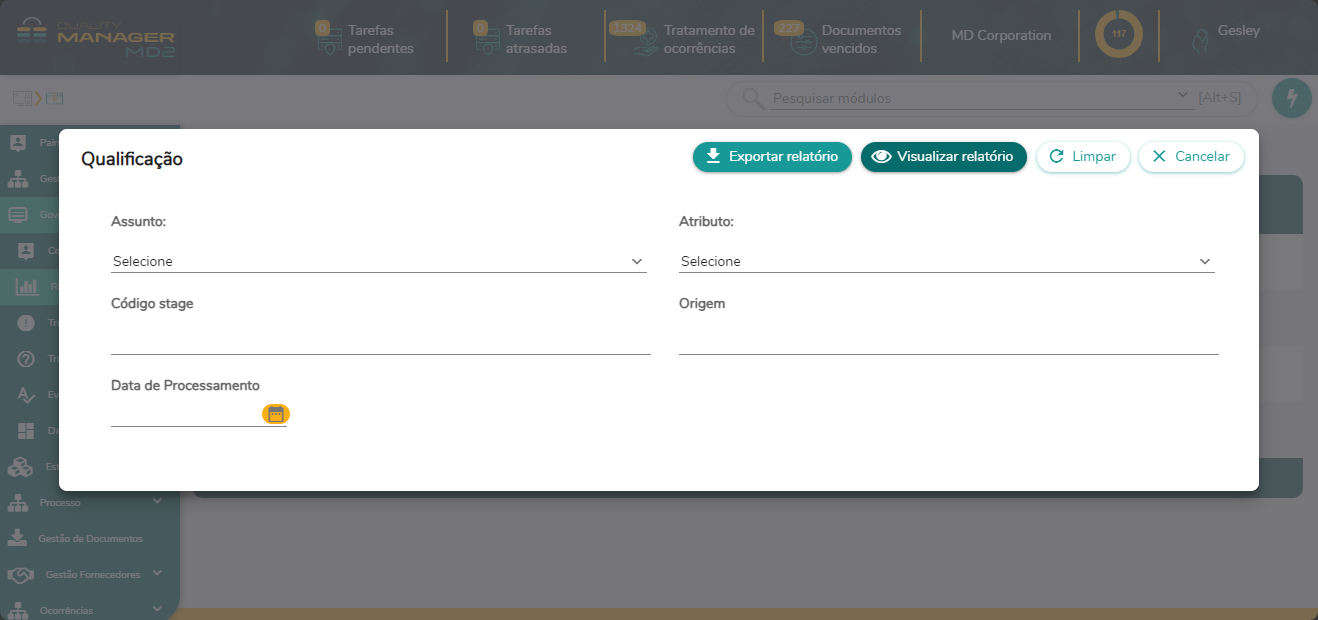
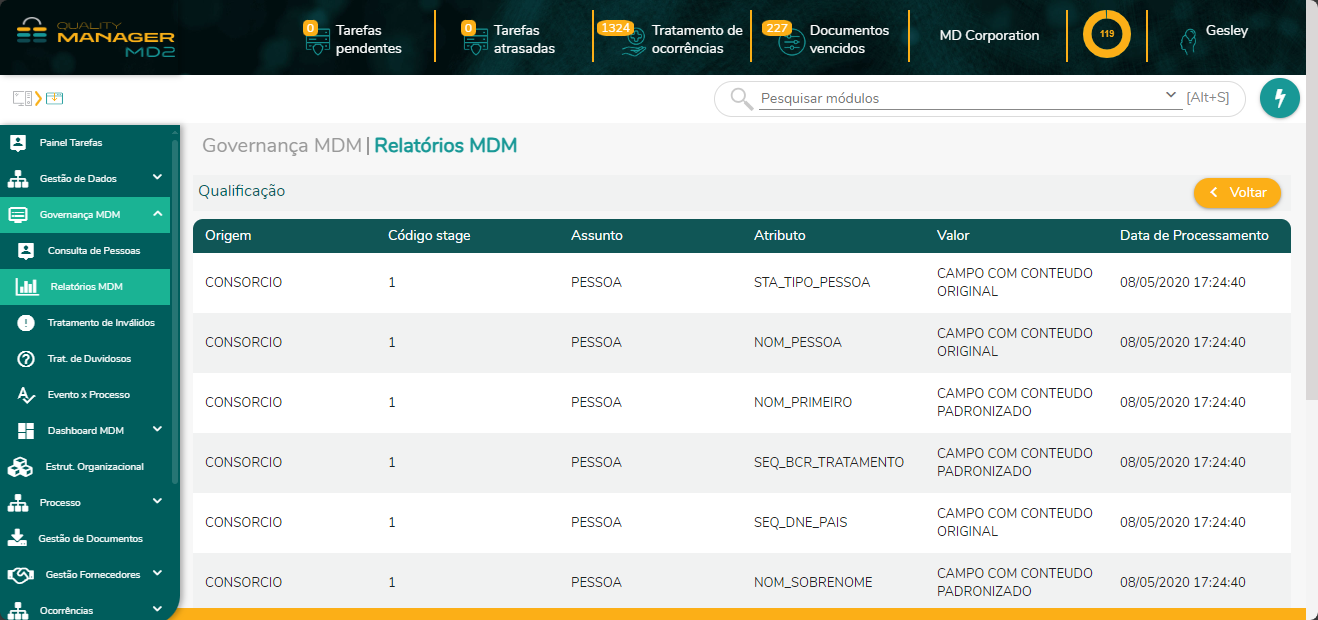
12.4. Unificação
Relatório que permite a consulta e emissão dos dados que foram unificados. Informando os sequenciais referentes as camadas BUP e STG, número do passo de matching, data início vigência, data fim vigência e assunto.
A compreensão do significado de cada número (passo) de maching é possível via consulta no InfoSphere Information Governance Catalog, onde mantemos as definições relacionadas as regras utilizadas para prover a unificação dos dados mestres, visando a publicação e disponibilização das informações de forma corporativa.
Possibilita filtrar a unificação dos dados por assunto, número do passo de matching, data de início da vigência e data de fim da vigência.